Application of OCR in Archive Digitization
The article introduces how OCR is applied as a process, and how the accuracy of OCR can be improved through various methods.
 100% Secure |
100% Secure | Home
>
Top OCR Software
> Application of OCR in Archive Digitization
Home
>
Top OCR Software
> Application of OCR in Archive Digitization
PDF technology has greatly advanced the realm of archive digitization over the past few decades. What was once a challenging task for data preservation and the ability to store documents for easy retrieval has now become commonplace. One of the key factors that drove this change is OCR or optical character recognition. Let’s see why OCR plays such an important role in archive digitization, how it is applied as a process, and how the accuracy of OCR can be improved through various methods.


 G2 Rating: 4.5/5 |
G2 Rating: 4.5/5 | 100% Secure
100% Secure
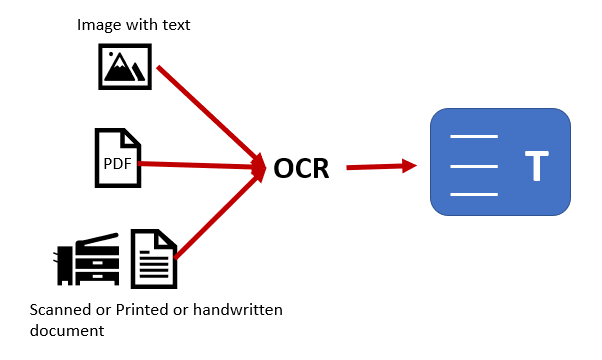
Part 1. Application of OCR in Archive Digitization
OCR is essentially the process of recognizing, extracting, and embedding the text content from an image-based digital or physical document into the existing image layer. This double-layer technology is supported by PDF, making it an ideal medium for archive digitalization. There are several other considerations that make PDF the perfect vehicle to digitize document archives.
1. Innovating on Traditional Cataloging and Indexing Methodologies
Cataloging and indexing often go hand in hand but are two entirely different processes. While cataloging is the organizing of assets or content items, indexing is related to the retrieval of information. Both are required when archiving documents, audio-visual media, newspapers, magazines, academic journals, and other types of content. Cataloging tells you what’s available, while indexing offers a way to find the correct information you’re looking for.
Converting physical documents or scanned files to PDF allows both cataloging and indexing to happen at the same time using OCR technology. The digitized content can be made editable or searchable, allowing for easy archive cataloging as well as archive indexing. Therefore, OCR is actually a new way to catalog and index document archives, making the process accessible through computers.
2. Realizing True Full-Text Retrieval
Manual indexing is typically prone to human error, which can range from 3% to as high as 30% depending on the task at hand. This means text-based documents may not be properly indexed if the process is conducted manually. The same goes for cataloging as well but to a lesser degree. However, with the help of OCR, conversion is possible up to an accuracy rate of 98% to 99%. In turn, this allows for full-text search and retrieval. When this capability is taken in tandem with metadata and indexing elements, it gives rise to an enhanced cataloging and indexing system.
3. Double-layer PDF Technology
Although the general understanding is that OCR embeds a layer of text onto the existing image, in reality, it is rendered as invisible text within the PDF. However, this text can now be selected and is therefore searchable. In the archive digitization process, the archivist will first verify if the digitized text layer is consistent with the text in the original image. This quality assurance step is critical to the accuracy of the rendered text. Such modifications will then be stored in the OCR-ed copy of the file, making it easier to search with keywords. Any typos that are left out during this quality assurance check will render the document unsearchable for that particular keyword. That’s where the layering factors in. It allows the archiver to visually check if the characters recognized by the OCR engine are consistent with the characters in the original image-based file.
4. Expanding the Use of Archived Files
Performing OCR on a PDF document renders a searchable layer, but it can also make the text editable. However, for the purpose of archiving and retrieval, a searchable document is preferred because the indexing information can aid in returning full-text search results. In turn, this allows OCR-ed documents to be used in a variety of scenarios based on whether it is editable or searchable. For instance, it is much easier to correct a piece of text in an image-based file using OCR than it is to correct that same text in an image editing tool. OCR opens up a range of such use case possibilities that traditional archiving techniques cannot match.
Part 2. How to Improve OCR Recognition Rate
The accuracy of an OCR run is dependent on various software-based as well as manual considerations, and these are listed below. Each of these parameters allows OCR to be more accurate, and they can either be controlled at the pre-OCR stage or the post-OCR stage, during quality assurance.
1. Using the Right Software - PDFelement
The OCR plugin in Wondershare PDFelement - PDF Editor Wondershare PDFelement Wondershare PDFelement is highly accurate and works with multiple languages, even simultaneously. In addition, PDFelement offers conversion to both searchable as well as editable versions of the original PDF file. It can also directly create a PDF using the input from a scanner, as well as convert non-text file formats into editable/searchable PDFs.
G2 Rating: 4.5/5 |100% Secure
2. The Right Scan Parameters
When scanning documents, it is important to set the right parameters in your scanner settings. Some of them are. The foremost of these is orientation. Ensure that the document is fed into the scanner at the correct angle because a skewed scan can seriously affect OCR accuracy.
3. Resolution Setting
The best resolution for accurate OCR is 300 dpi or dots per inch. This higher density allows for a ‘tighter’ scan, enabling the OCR engine to work with double the number of reference points when compared to 150 dpi.
4. Color Mode Selection
For discolored or old documents, RGB is the recommended color mode to enable the scanner to fully capture the contents of the physical document. In general, however, scanning in grayscale mode is the best option for OCR accuracy. Although the Black and White mode helps the image be scanned at a faster rate, this could affect the quality of text recognition.
5. Brightness and Contrast Adjustments
For brightness, both extremes - too high or too low - can negatively affect OCR quality and accuracy. For that reason, 50% is the recommended brightness setting. However, this is also dependent on the scanner itself so an initial trial and error phase may be expected.
In terms of contrast, the highest setting is usually preferred because OCR essentially works by analyzing dark and light areas to identify individual characters. Rules are then applied to match these results with known characters, text, and numbers. If the contrast between the dark portion of the text is high relative to the surrounding non-text portions, OCR is more accurate.
6. Image Correction and Decontamination
These two components greatly impact the quality of OCR scanning. Image correction covers aspects such as increasing the resolution, applying color corrections and trying out different contrast settings, while decontamination involves the removal of non-text characters such as icons, non-text images, unusual characters, and so on. Both are important because they enable the OCR engine to ‘read’ the document more accurately.
7. Careful Manual Proofreading
Depending on how accurate you want the end result to be, manual proofreading may or may not be required. If accuracy is paramount, then this is an indispensable step in the archive digitization process. It essentially involves human verification to ensure that the scanned characters are recognized correctly in the context of the scanned image. It’s a tedious and painstaking process but essential in many cases.
PDFelement-The Best OCR Software for Archive Digitization
PDFelement offers a highly accurate OCR engine, but also brings several other advantages to the table when it comes to archive digitization. Here are some of the features that make it the perfect software for OCR PDFs and scans.
G2 Rating: 4.5/5 |100% Secure
- Full editing capabilities - Once converted into an editable PDF, a document can be easily modified using the editing tools for images, text, tables, graphs, footers/headers, watermarks, hyperlinks, and other content.
- Multi-lingual OCR - If you have a document with more than one language present, you can confidently use PDFelement for the OCR process. It supports over 20 languages, which helps increase the overall accuracy of text recognition.
- Batch Process - OCR can be done on a batch of documents, thereby saving time in the digital archiving process.
- Annotations - Converted files can be annotated with notes, highlighting, and other content, which aids the indexing process. The annotation list and tabbed layout of PDFelement make it easy to cross-reference texts when researching a particular topic using OCR-ed files.
- E-Signing and Security - Files can be digitally or electronically signed as well as protected from unauthorized viewing or editing using password-based encryption. This helps validate the authenticity of a document and prevents any changes from being made. Redaction is another useful feature that users can utilize to prevent sensitive information from being searchable.
- File and Page Organizing - Easy ways to split and merge files, create PDF portfolios, compare documents after OCR, add/delete/reorder pages, extract pages, etc.
- File Size Reduction - The PDF Optimize feature in PDFelement helps archivists store large amounts of information in a very efficient manner.
For these and other reasons, PDFelement is considered to be one of the best PDF editors for OCR and related tasks. The software is also one of the most affordable premium PDF utilities for small companies as well as enterprise-level organizations, making it a viable solution for companies, educational institutions, and all manner of entities across government, public, and private sectors.
Free Download or Buy PDFelement right now!
Free Download or Buy PDFelement right now!
Try for Free right now!
Try for Free right now!


Audrey Goodwin
chief Editor