
PDFelement-Powerful and Simple PDF Editor
Get started with the easiest way to manage PDFs with PDFelement!
With optical character recognition (OCR), you can convert a scanned document into an editable and searchable text file. It has various applications and may be accomplished partly by using open-source tools.
Getting an open source is a feasible option for people wishing to modify the OCR according to their requirements. If you want to get an excellent OCR Open Source tool, we've got you covered. In this article, you'll discover the finest tools to perform OCR online and why people need them. Let's get going!

In this article
Why Do People Need an Open Source OCR tool?
Some of the reasons why people need an open -source OCR tools are:
- If you wish to modify OCR according to your requirements, you will want an open-source OCR.
- Since open-source OCR is more flexible and modifiable than the OCR tools, it can serve you better who wish to add something innovative to the program later.
- Since most OCR software requires extra charge, you won't wish to buy a subscription if you need the software once or twice a month. In this scenario, you might want to have open source OCR software for the job.
Top 4 Best Open Source OCR Tools in 2022
Now that you know why you require open source OCR software, you might be looking for the best option. That's what you'll find in this section. Here, we've reviewed the best tools OCR PDF open source tools, which include:
1. Tesseract OCR
Hewlett-Packard's Tesseract is widely regarded as the best open-source OCR engine. It's open source software released under the Apache license and has had Google's backing since 2006. The Tesseract OCR engine is also one of the most precise and widely accessible open-source solutions. Tesseract's newest stable version, 4.1.1, is based on LSTM and can process text in up to 116 languages.
Because it is run from the command line (CIL), Tesseract does not have a graphical user interface (GUI). With its advanced picture pre-processing pipeline and neural network learning capabilities, it can acquire new knowledge. Moreover, language, picture quality, data training, page segmentation, and engine all have a role in how accurate the result is.
Images can be preprocessed with libraries like OpenCV and ImageMagick to eliminate noise, resize, binarize, rotate, invert, dilate, and erode for more precise results using this open source OCR python tool.
Key features
- It works with many languages and has wrappers for many of them, including Java, Python, Ruby, and Swift.
- It's compatible with other programs for making GUIs.
- To load images, its engine consults the open source OCR library, such as Leptonica.
- It provides many opportunities for people to get involved in their communities.
- Languages It Supports: 116 Languages, including English, Spanish, Hindi, Polish, Portuguese, and others.
Pros
Supports multiple programming languages
Better accuracy than competitors
Cons
Hard for a novice to understand
To perform opensource PDF OCR using Tesseract OCR, follow the steps below:
Step 1 First, get the latest installer for Tesseract. Open the Command prompt and write pip install pytesseract to install it.
Step 2 Now, you need to read the image. Go to Google Colab, and write the following code: Note: In cmd=r, you need to give the path of tesseract.exe on your computer. In cv2.imread, you need to provide the name of the image you have uploaded to Colab.

Step 3 After reading the image, it is time to convert the image text to string. For that, you need to add the following chunk of code:

Step 4 When you run the code, you will get the image text as an output.
2.Azure OCR
The Azure OCR API in the cloud gives programmers access to advanced text-reading algorithms that provide structured data from scanned photos. Microsoft Azure's OCR tools allow for mining printed typescript in several languages, handwritten text in many languages, and currency symbols from pictures, numbers, and multi-page PDF brochures.
The Azure Cognitive Service, Computer Vision, is an artificial intelligence (AI) service that evaluates still images and moving ones for relevant information. Among the many features offered by Azure OCR is access to Azure Cognitive Services, a computer vision API.
Languages It Supports: 10+ languages, including English, Japanese, Spanish, etc.
Key features
- Three cloud services are available, and you can compare how well their OCR algorithms work.
- Because of this, developers can easily add pre-built AI functionality to their software.
- Because of the portability of containers, you can use the same rich APIs accessible in Azure.
- Information in various languages and scripts, printed and handwritten, can be retrieved.
Pros
AI-based scripts for OCR
Proper accuracy
Cons
Difficult for normal users
To carry out OCR using Azure OCR, follow the steps below:
Step 1 Visit the Azure Portal on your preferred browser. To access Cognitive Services, go to the AI + Machine Learning section under All services in the main menu.
Step 2 Choose Computer Vision, Create, and set up the form.
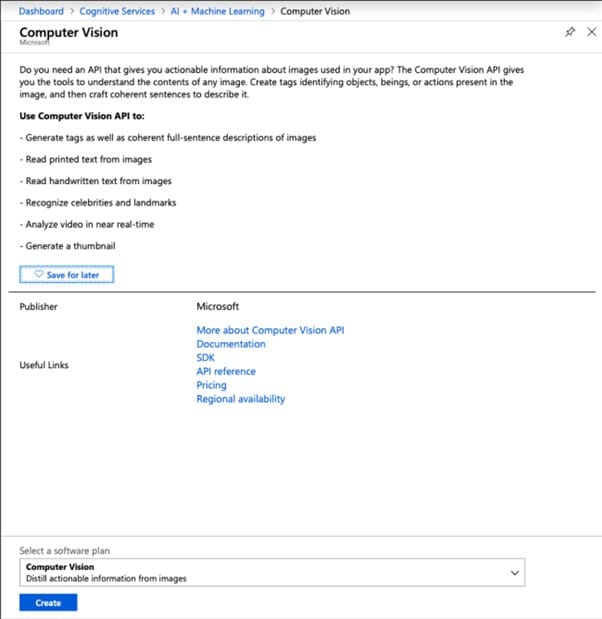
Step 3 To access the OCR-Test resource, go to the Dashboard. To access Keys, choose it from the Resource Management submenu.
Step 4 There will be two keys visible; please copy KEY 1. Write the following code into Google Colab.
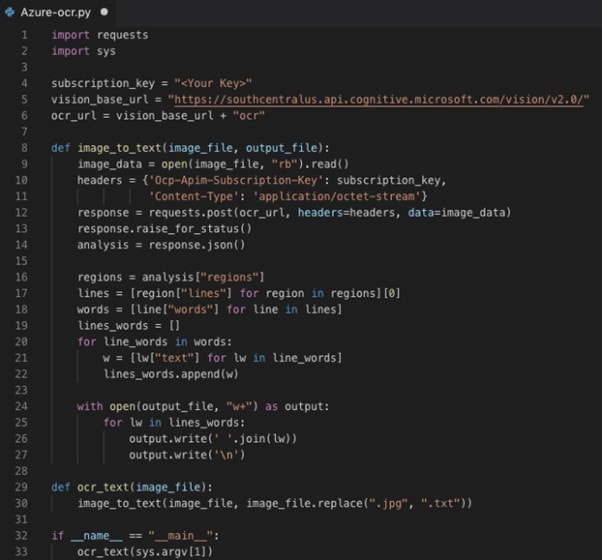
Step 5 The code, when executed, will provide textual output on the console, which will be the text extracted from the picture.
3.Abbyy OCR
When you scan a printed or handwritten page into ABBYY OCR, you can convert it into an editable document copy. It has a language detection capacity of over 200. You can convert PDF/image files to Word, Excel, PDF, etc., text searchable formats with the aid of this program. Recognized information is transformed into XML (Extensible Markup Language). This resource is a Java, .NET, iOS, and Python library.
You may annotate and markup documents, add security measures like passwords and digital signatures, verify documents using these, and more. The app's time-saving functions make it easier to work on projects together.
Languages It Supports: Works with 200 languages, including Russian, Hebrew, Chinese, Farsi, and others.
Key features
- Compatible with various tongues, including Japanese, Korean, Arabic, Farsi, Vietnamese, and Thai.
- You can export your documents to Word, Excel, or PowerPoint.
- Put the resulting archive in a cloud storage service like Google Drive.
- The UI is sleek and intuitive, making it a breeze to make changes and arrange files.
Pros
Fast and quick
Easy collaboration
Cons
Quite expensive
4.OCR Space
If you need to transform scanned photos or PDFs into editable documents, go no further than OCR Space. It's a web-based, free OCR tool that employs four different OCR engines to pull text out of photos and PDFs and display it in an overlay. OCR Space is an easy-to-use online tool for transforming scanned documents and PDFs into editable text that can be searched digitally.
To convert a document to editable files, you may either upload the file or paste the URL. The program can determine when a picture needs to be enlarged and does so automatically.
Languages It Supports: 20+ languages, including English, Hindi, Russian, Spanish, etc.
Key features
- Speedily scan documents, including complicated table layouts, such as receipts.
- You can find out how a picture is oriented and auto-rotate it if it's wrong.
- It supports files with poorly contrasted text against a complicated backdrop.
- Maximize OCR accuracy by automatically enlarging picture files or document content.
Pros
Completely online
No need to sign in
Cons
Cannot generate output in Word document
To perform OCR using OCR Space, follow the step below:
Step 1 Go to OCR Space, and select a picture or PDF from your computer by clicking the Choose file button. Images in PNG, JPG, and WebP formats are all supported by OCR Space. You can also enter or paste the URL of the image or PDF's source file.
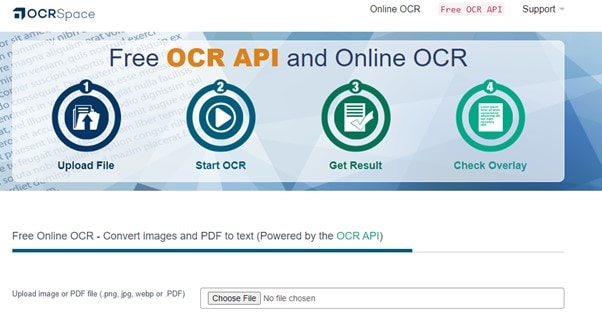
Step 2 Click the Language tab to set the language according to the text in the image or PDF. You have three choices in OCR Space from which to choose before beginning the OCR process. Select the options according to your requirements.
Step 3 When you've chosen the engines next to the Select OCR Engine to use option, click Start OCR to begin the scanning process.
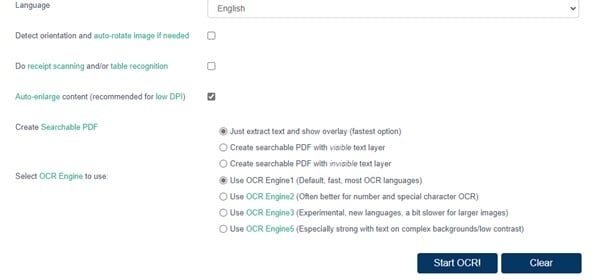
Step 4 After completing the process, you will get an output in text form next to the image or PDF. You can make changes, choose Download, or copy and paste into a text editor.
Best Tool for PDF OCRs on Windows and iOS
Wish to find the best tool for PDF OCR for Windows and iOS devices? You'll find it in this section. Although the above tools are the best for open-source OCR, they cannot edit PDFs in any situation. For that, you require quality software, such as Wondershare PDFelement - PDF Editor Wondershare PDFelement Wondershare PDFelement.
PDF is suited to the task of handling all PDF demands. Users can easily edit scanned documents and benefit from the ability to convert OCR-recognized texts to commonly used formats, including Microsoft Word, Excel, HTML, and PowerPoint. Customizable text fields, stamps, and comments are also part of the tool. Making content as a team is a breeze with this tool.


 G2 Rating: 4.5/5 |
G2 Rating: 4.5/5 | 100% Secure
100% Secure
Key Features
- Images and scanned documents with text inside them can be recognized.
- It allows users to extract text from a scanned PDF or picture and use it for other purposes, such as copying or searching.
- Quick processing times and rich editing tools let you create a PDF that stands out.
- With its user-friendly interface, even novices can quickly get up to speed.
What We Like
Easy to search text in PDF
Can convert the OCR result into a Word format
Proper customization tool
What We Dislike
You cannot use some editing features for free
Pricing: Free to $7.99
Languages It Supports: It supports up to 29 different languages.
To perform PDF OCR via PDFelement, follow the steps below:
Step 1 Get PDFelement on your device, and launch. Click on the + icon or drag and drop your PDF to upload it.
G2 Rating: 4.5/5 |100% Secure
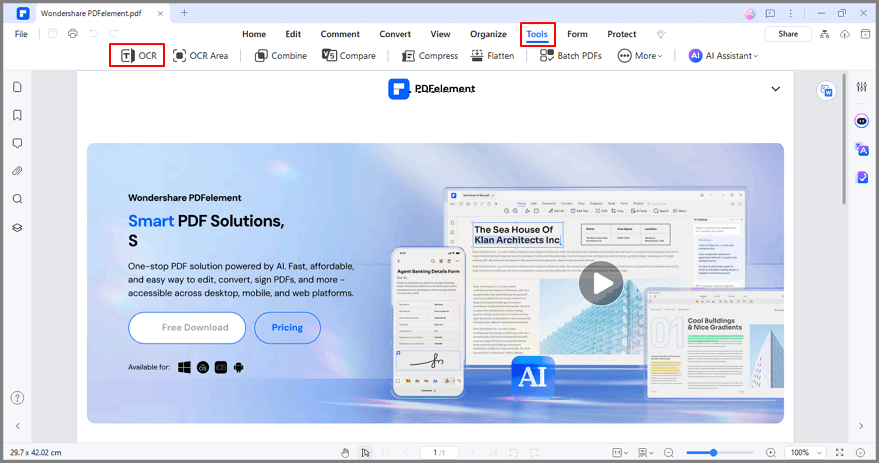
Step 2 Click on Tool and then OCR to proceed. A window will appear; select Editable Text and then select the language by clicking on Choose Language. Then, click on OK to start the scan.
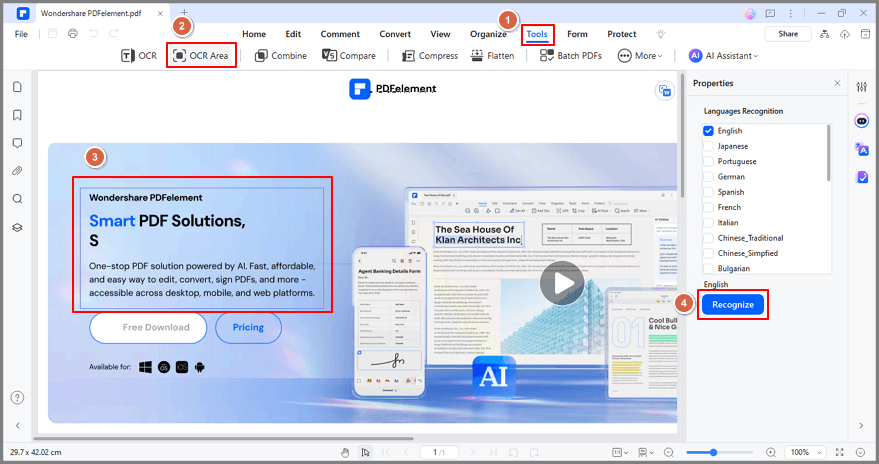
Step 3 After the scan, you can click on Edit to edit the PDF text or To Text to export the editable text to your computer.
Conclusion
Open-source OCR tools allow people to easily extract text from images and PDFs without downloading the software. It also allows the user to modify the tool as per their requirement. With the OCR Open Source tools discussed in this article, we hope you've found the right one. Moreover, if you wish to do PDF OCR on Windows or iOS device, our top recommendation is PDFelement.

