
A small business owner scans dozens of invoices every week, struggling to organize them into spreadsheets for bookkeeping. Each image holds valuable information but manually typing data wastes time and invites errors. Extracting data from images offers a practical solution, turning these pictures into structured, editable formats in seconds.
With the right tools, numbers, text, and tables can be captured accurately and exported to Excel, Google Sheets, or other applications. Whether handling receipts, forms, or handwritten notes, this process streamlines workflow and improves efficiency. Read the article till the end to learn all about data extraction from images.
In this article
- Reasons People Need to Extract Data from Picture
- What "Extracting Data from an Image" Actually Means
- Types of Data Commonly Extracted from Images
- Why Images Are Harder to Process Than PDFs
- How Image Data Extraction Works at a High Level
- Common Methods to Extract Data from a Picture
- Extracting Data from Images with PDFelement
- Extracting Image Data into Excel Workflows
- Improving Accuracy When Extracting Data from Images
- Common Mistakes in Image Data Extraction
Part 1. Reasons People Need to Extract Data from Picture
Extracting data from pictures has become essential for saving time and improving accuracy in everyday tasks. Instead of manually typing information, users can quickly turn images into structured, editable data. Mentioned below are some of the reasons why people prefer this approach:
- Document Management: Extracting data from pictures allows users, such as office managers, to digitize contracts, reports, and forms quickly. This reduces manual typing and ensures accurate storage in databases or spreadsheets.
- Table and Spreadsheet Capture: Professionals often take screenshots of financial tables or schedules. It converts these images into editable formats for analysis without re-entering numbers.
- Scanned Records: Archivists and administrators deal with scanned paper records regularly. By extracting data, they can organize historical information efficiently for retrieval and reporting.
- Business Card Digitization: Sales teams and networkers receive stacks of business cards. Extracting data helps store contact details directly into CRM systems without errors.
- Receipt and Invoice Tracking: Accountants and small business owners capture receipts and invoices for bookkeeping. Data extraction simplifies expense tracking and financial record-keeping automatically.

Why Images Often Become the Only Available Data Source
In many situations, images are the only record of information. Receipts, handwritten notes, whiteboard content, or screenshots of online data are often not available in editable formats. Businesses and individuals rely on photos to preserve critical details when original files are lost or never existed digitally. Extracting data from the picture ensures that this information can be organized, analyzed, and reused efficiently without manual transcription.


 G2 Rating: 4.5/5 |
G2 Rating: 4.5/5 | 100% Secure
100% Secure
Part 2. What "Extracting Data from an Image" Actually Means
After understanding why images often serve as the only data source, it's important to clarify what extracting data from an image to Excel entails. This process involves using tools or software to identify and convert text into editable and searchable digital formats.
Difference Between Reading Text Visually and Extracting Usable Data
Reading Text Visually: This is what humans do when they look at an image and understand its content. It allows comprehension but does not make the information editable or actionable in digital tools.
Extracting Usable Data: This involves converting the information in an image into structured, machine-readable formats. Tools can capture text, tables, and numbers automatically, enabling editing, analysis, and integration into spreadsheets or databases.

Text Extraction vs. Structured Data Extraction
Once you understand the difference between reading text visually and extracting usable data, it's helpful to distinguish between simple text extraction and structured data extraction. While both involve capturing information from images, their applications, accuracy, and output formats differ significantly. The table below highlights these differences clearly:
| Feature | Text Extraction | Structured Data Extraction |
| Definition | Captures raw text from an image | Converts text into organized, structured formats like tables or spreadsheets |
| Output | Plain text, often unformatted | Editable tables, fields, or database-ready entries |
| Use Cases | Scanned notes, paragraphs, or images | Invoices, receipts, forms, business cards, or charts |
| Complexity | Simple, requires basic OCR | Advanced, may involve AI or pattern recognition for accurate structuring |
Why Layout and Context Matter in Data Extraction
The arrangement and context of information in an image significantly impact the accuracy and usefulness of extracted data. Properly recognizing structure ensures that numbers, text, and tables are interpreted correctly. Here is why layout and context matter when extracting data from pictures:
- Invoice Processing: Consistent invoice layouts ensure amounts, dates, and vendor names are correctly assigned to the right fields.
- Form Digitization: Maintaining layout integrity in standardized forms prevents the mismatching of entries like addresses, phone numbers, or ID numbers.
- Table Interpretation: Preserving row and column structure in tables ensures data relationships are retained for accurate analysis.
- Handwritten Notes: Context helps distinguish headings, subpoints, and annotations in handwritten notes for clarity in digital versions.
- Receipts and Bills: Recognizing layout prevents confusion between totals, taxes, and individual item prices in receipts and bills.
G2 Rating: 4.5/5 |100% Secure
Part 3. Types of Data Commonly Extracted from Images
After understanding why layout and context are important, it's useful to explore the kinds of data that are most often extracted from images. Different types of content require different extraction approaches, and knowing these helps choose the right tools for extracting a table from an image to Excel.
Plain Text (Names, Numbers)
Plain text extraction focuses on capturing individual words, phrases, or numeric values from an image. This includes names, addresses, phone numbers, serial numbers, or any standalone text. Tools can quickly recognize and convert these elements into editable formats. This makes it easy to store or reuse without manually typing each detail.
Tables (Rows and Columns)
Tables contain structured data organized in rows and columns, such as financial statements, schedules, or product lists. Extracting tables ensures that relationships between rows and columns are preserved. It allows the data to be exported directly into Excel, Google Sheets, or database systems for analysis and reporting.
Mixed Layouts (Labels + Values)
Mixed layouts combine labels and corresponding values, commonly seen in forms, invoices, or receipts. Extracting this type of data requires understanding the relationship between the label and its value to maintain accuracy, so each piece of information is mapped correctly in a structured format.

Why Tables Are the Hardest to Extract Accurately
- Complex Formatting: Tables with merged cells, nested headers, or irregular spacing make it difficult for software to recognize rows and columns accurately.
- Mixed Data Types: Tables containing numbers, text, and symbols together require careful extraction to preserve context. Extracting each type correctly can be challenging.
- Skewed or Low-Quality Images: Tilted or blurry scanned or photographed tables distort alignment. These distortions prevent accurate data capture.
- Dynamic Layouts: Tables with varying column widths or hidden totals create inconsistencies. Such layouts confuse extraction tools, requiring advanced AI or manual correction.
Part 4. Why Images Are Harder to Process Than PDFs
While learning about how to extract data from an image, it is important for you to know why images are harder to process. Mentioned below are some of the reasons explaining why images are harder to process than PDFs:
- Lack of Embedded Structure: Scanned images store text as pixels rather than editable text. Unlike PDFs, there's no metadata or embedded text to guide extraction, making OCR more error-prone.
- Blurred Images: Photos taken with shaky hands or low-resolution cameras produce blurred characters. This reduces OCR clarity, causing misreads or skipped data.
- Shadows and Lighting Issues: Uneven lighting or shadows on documents can obscure text. This makes it difficult for software to detect characters correctly.
- Perspective Distortion: Capturing notes or documents at an angle skews rows and columns. Distorted perspectives lead to misaligned or incomplete data extraction.
- Background Noise: Images with patterned backgrounds, stains, or watermarks add visual noise. This confuses OCR tools, resulting in false characters or symbols.

How These Factors Affect Recognition Accuracy
Image imperfections like blur, shadows, perspective distortion, and background noise make it harder for OCR tools to correctly identify characters. Lack of embedded structure adds to the challenge, as software must rely solely on visual cues. Handwriting variations and low-resolution images further increase errors. Together, these issues lead to misread, skipped, or misaligned data.
Part 5. How Image Data Extraction Works at a High Level
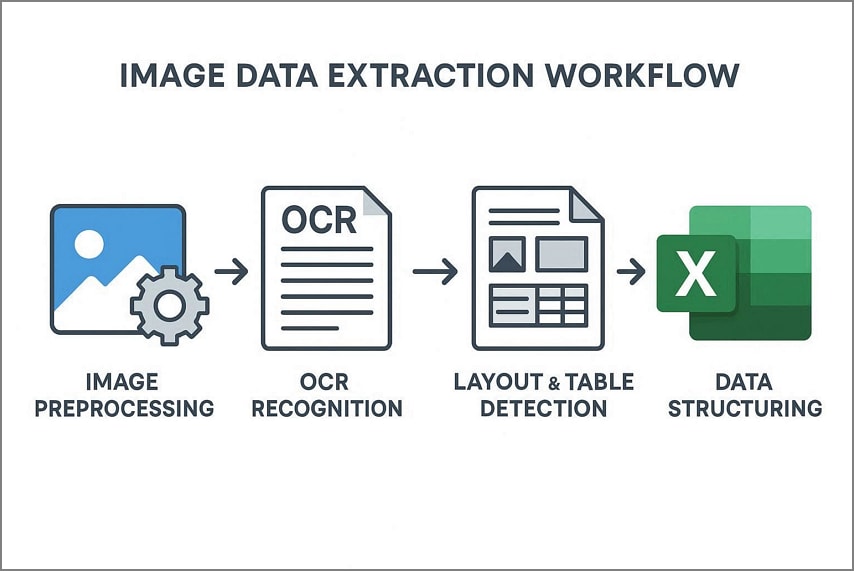
Before you extract data from an image to Excel, it's important to understand the overall process behind the scenes. Mentioned below is the workflow of how image data extractions work:
Image Preprocessing
The image is first cleaned and optimized. This may include noise reduction, contrast adjustment, binarization, and alignment correction to improve clarity and readability.
OCR for Text Recognition
Optical Character Recognition analyzes the processed image to detect and convert visible characters into machine-readable text. This step transforms pixels into digital text strings.
Layout and Table Detection
The system then analyzes spatial relationships to identify headings, paragraphs, rows, columns, and label-value pairs. Preserving layout ensures data relationships remain intact.
Data Structuring
Finally, the recognized content is organized into structured formats such as tables or fields. This structured output can then be exported to Excel or other data-driven platforms for analysis.
Part 6. Common Methods to Extract Data from a Picture
Various approaches help convert text, tables, and other information from pictures into structured, editable formats. Mentioned below are some of the top methods to extract data from a picture:
Manual Transcription
Manual transcription involves typing the information from an image by hand. While it requires no special software, this method is time-consuming, prone to human error, and impractical for large volumes of data, making it suitable only for small or one-off tasks.
Copying Text from Image Viewers
Some image viewers and PDF readers allow users to select and copy text directly from images. This method works if the software supports basic OCR, but it often struggles with complex layouts, handwritten content, or low-quality images, limiting its accuracy and usefulness.
OCR-Based Extraction Tools
Optical Character Recognition (OCR) tools automatically identify and convert text from images into editable digital formats. Advanced OCR software can handle printed documents, receipts, forms, and even tables, significantly speeding up data entry while reducing errors compared to manual methods. Many modern OCR solutions also support batch processing and integration with spreadsheets or databases.
Why Most Methods Fail at Scale
Manual transcription and simple copy-paste methods become impractical for large volumes of images due to time and labor constraints. Even basic OCR tools struggle with varied layouts, poor image quality, or mixed data types. At scale, these limitations lead to increased errors, inconsistencies, and delays, making it difficult to maintain accuracy and efficiency.
Part 7. Extracting Data from Images with PDFelement
PDFelement is designed to deliver high image-to-structure accuracy when extracting data from images. Unlike basic OCR tools that only capture raw text, its advanced OCR engine recognizes text, tables, and mixed layouts while preserving formatting and alignment. It performs reliably even with real-world image conditions such as slight blur, uneven lighting, or skewed angles.
The software intelligently detects rows, columns, and label-value pairs, ensuring structured output rather than fragmented text. With direct export options to Excel and editable formats, PDFelement helps convert images into accurate, reusable, and professionally structured data.
G2 Rating: 4.5/5 |100% Secure
Steps For Extracting Data From Images with PDFelement
As discussed, PDFelement allows users to get text and data from images effortlessly. To learn how to perform this, read the steps provided next:
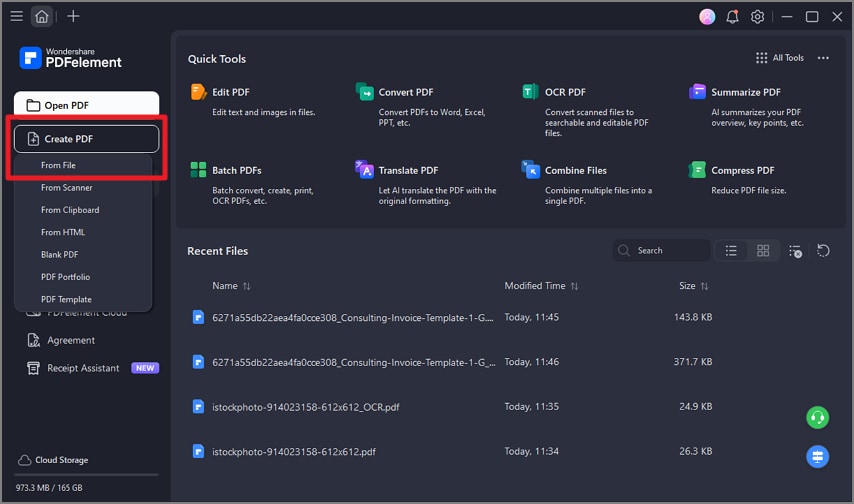
Step 1Begin By Importing Image
Launch PDFelement and go to the top-left corner to select "Create PDF." From the expanded list, choose the "From File" option and import the image for extraction.
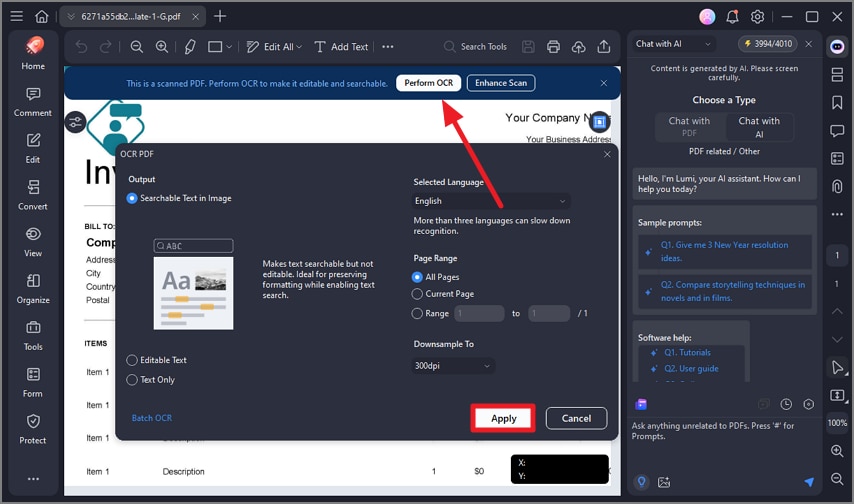
Step 2Apply OCR On Image
Once the image is imported, the tool will automatically detect if it needs OCR. Press the "Perform OCR" button above the page. Now select the mode and language for the PCR and press the "Apply" button to execute the process.
G2 Rating: 4.5/5 |100% Secure
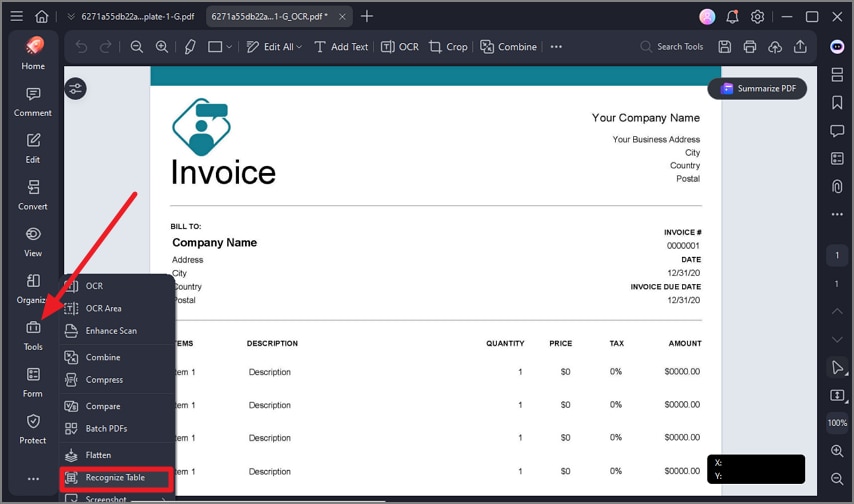
Step 3Recognize the Table in The Image
Now, head to the toolbar on the left and click on the "Tools" options. Choose the "Recognize Table" option to detect tables and structured layouts.
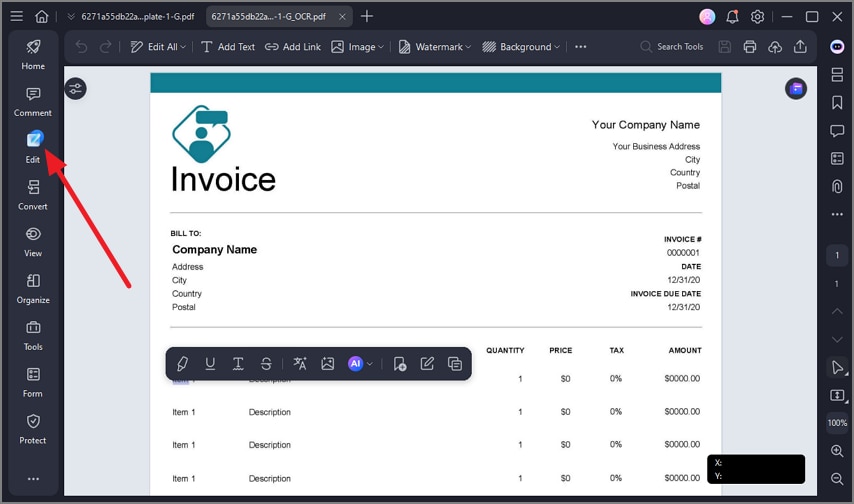
Step 4Edit The Extracted Data
Once the tables are extracted, enable the "Edit" section and review and edit the data according to your preferences.
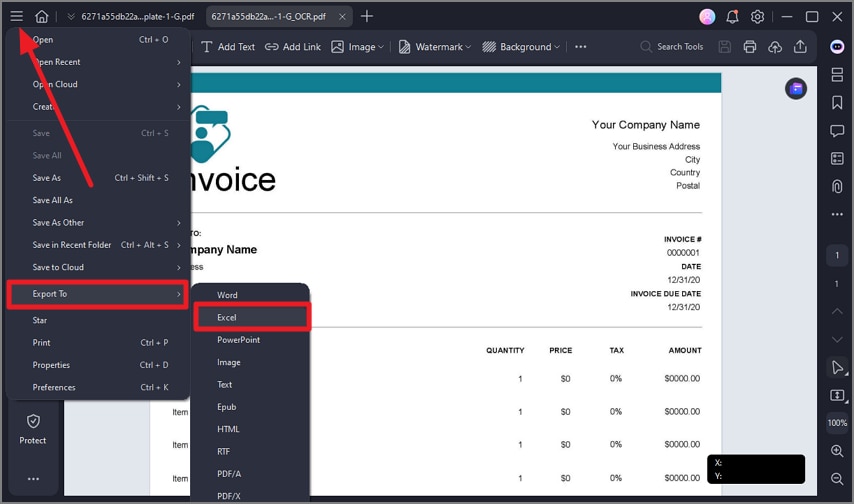
Step 5Save As Excel File
When the editing is done, head to the top-left corner and press the "Three Bars" icon. Choose the "Export To" option from the extended list and select "Excel" to save the file as an Excel sheet.
Part 8. Extracting Image Data into Excel Workflows
Excel is the best destination when the extracted data from an image needs calculation, sorting, filtering, or reporting. Structured tables, financial records, invoices, and survey results benefit from Excel's formulas and data analysis features. Exporting directly to Excel preserves rows and columns, enabling immediate use without reformatting. This makes it ideal for accounting, tracking operations, performance analysis, and any workflow requiring organized, actionable data.
G2 Rating: 4.5/5 |100% Secure
How to Prepare Extracted Data for Analysis
- Verify Extracted Content: Cross-check the extracted data against the original image to identify OCR misreads, missing fields, or misplaced values before analysis begins.
- Standardize Formatting: Ensure consistent date formats, currency symbols, number formats, and text capitalization. Uniform formatting prevents formula errors and improves sorting or filtering accuracy.
- Clean Unnecessary Characters: Remove extra spaces, line breaks, special symbols, or duplicated entries that may have been introduced during extraction.
- Validate Table Structure: Confirm that rows and columns align correctly and that headers match their respective data fields. Proper structure is essential for accurate calculations.
- Check Data Types: Convert text-based numbers into numeric formats and verify that dates and percentages are correctly recognized to enable reliable formulas and analytics.
Why Review is Critical Before Spreadsheet Use
Reviewing extracted data before using it in a spreadsheet is critical to prevent calculation errors and flawed insights. Even small inaccuracies can distort totals, averages, or reports. A quick validation step ensures correct data types, proper alignment, and complete records, protecting analysis accuracy and maintaining confidence in downstream business decisions.
Part 9. Improving Accuracy When Extracting Data from Images
Small adjustments in image capture, preprocessing, and validation can significantly reduce errors and enhance accuracy. The section below discusses how you can improve accuracy while extracting the data from images:
Capture Tips for Clearer and More Accurate Image Data
Improving the quality of images at the capture stage can dramatically enhance accuracy when extracting data from images to Excel. Simple adjustments and best practices help OCR and AI tools recognize text and structure more reliably.
- Use High-Resolution Images: Ensure documents are captured in high resolution. Clearer images reduce OCR misreads and improve recognition of small fonts and fine details.
- Even Lighting: Avoid shadows or glare by using natural light or flatbed scanners. Consistent lighting ensures all text is visible and prevents misinterpretation.
- Straighten and Align: Take pictures from directly above the page. Proper alignment reduces perspective distortion, making rows, columns, and labels easier to detect.
- Minimal Background Noise: Place documents on plain backgrounds. Eliminating patterns, stains, or other distractions helps OCR focus only on relevant text.
- Steady Capture: Use tripods or stable surfaces when photographing documents. Reducing motion blur ensures that every character is sharp and readable for extraction.
Preprocessing Strategies to Enhance Data Extraction
- Denoising and Cleaning: Remove background noise, stains, or smudges from scanned documents. Cleaner images reduce false character detection and improve text clarity when extracting data from images.
- Contrast and Brightness Adjustment: Enhance contrast and adjust brightness. A clearer distinction between text and background helps OCR distinguish characters more accurately.
- Deskewing and Alignment: Correct tilted or rotated images. Proper alignment preserves table structures and ensures labels and values match correctly.
- Cropping Irrelevant Areas: Crop out margins, borders, or logos. Focusing on relevant content reduces distractions and improves recognition efficiency.
Why Small Improvements in Image Quality Matter
Even minor enhancements in image quality can significantly improve data extraction accuracy. Slightly increasing resolution, correcting alignment, or improving lighting helps OCR tools recognize characters more precisely. Clearer edges and better contrast reduce misreads and skipped fields. Small adjustments also preserve table structure and label-value relationships.
Part 10. Common Mistakes in Image Data Extraction
While extracting data from pictures can streamline workflows, several common mistakes reduce accuracy and reliability. Recognizing these pitfalls helps ensure cleaner outputs and more dependable structured data.
- Treating OCR Text as Final Data: OCR output is often assumed to be error-free. In reality, minor recognition errors can occur, and failing to review results may lead to incorrect records or flawed analysis.
- Ignoring Table Structure: Extracting text without preserving rows and columns breaks data relationships. This can result in misplaced values and unusable spreadsheets.
- Over-Relying on Free Tools: Basic free tools may lack advanced layout detection or AI capabilities. This often leads to incomplete extraction or formatting issues.
- Skipping Validation: Failing to cross-check extracted data against the original image increases the risk of unnoticed errors. Validation ensures accuracy before data is stored or analyzed.
People Also Ask
-
How do I extract data from an image?
Use an OCR-based tool to scan the image and convert text or tables into editable formats. Tools like PDFelement offer built-in OCR that accurately extracts and converts image content into structured, usable data. -
Can data be extracted from pictures accurately?
Yes, data can be extracted accurately if the image quality is clear and properly aligned. Advanced OCR tools such as PDFelement improve accuracy by preserving layout and structure during conversion. -
What is the best way to extract data from an image to Excel?
The most effective method is using an OCR tool that supports direct export to Excel format. PDFelement allows you to convert image-based documents into editable Excel files while maintaining the table structure. -
How do I extract a table from an image to Excel?
Use software with advanced table recognition that detects rows and columns automatically. PDFelement's OCR feature can identify table layouts and export them directly to Excel with proper formatting. -
Do I need to clean data after image extraction?
In most cases, reviewing and validating extracted data is recommended to catch minor OCR errors. Even when using reliable tools like PDFelement, a quick check ensures maximum accuracy before analysis or reporting.
Conclusion
To sum it up, this article provided a detailed guide on how to extract data from an image. The article also explained that images are often unavoidable data sources, especially when documents exist only as photos, scans, or screenshots. Effective extraction goes beyond basic OCR, requiring proper structure recognition to preserve tables, labels, and relationships.
Careful review and validation are essential to protect downstream workflows from hidden errors. With advanced OCR and layout detection, PDFelement helps convert images into structured, reusable data confidently and efficiently.

