
In today's data-driven world, extracting information from PDF documents can be time-consuming and error-prone. Manually copying and pasting data from hundreds or thousands of PDF files is tedious and can lead to inaccuracies and inconsistencies in your data. However, with the power of automation, you can streamline your PDF data extraction process and save yourself valuable time and effort.
Automating PDF data extraction can provide many benefits, from improved accuracy and efficiency to increased productivity and scalability. By eliminating the need for manual data entry, you can reduce the risk of errors and free up your time to focus on more high-value tasks. In this article, we'll explore the process of automating PDF data extraction step-by-step.

Benefits of Extracting Data from PDF Automatically
Automating PDF data extraction can provide various benefits, making it a valuable tool for businesses and individuals. By reducing the time and effort required to extract data from PDF documents, you can improve your workflow and achieve better results. Here are some of the key benefits of automating PDF data extraction:
Time-saving: Manually extracting data from PDFs can be time-consuming, especially if you must process large documents. By automating the process, you can significantly reduce the time and effort required to extract data from PDFs, freeing up your time to focus on more high-value tasks.
Increased accuracy: Manually copying and pasting PDF data can be prone to errors, especially if you need to process large volumes of documents. By automating the process, you can eliminate the risk of errors and ensure that your data is accurate and consistent.
Improved productivity: Automating PDF data extraction can help you to improve your productivity by streamlining your workflow and reducing the time and effort required to complete routine tasks. This can help you to achieve more in less time, allowing you to focus on more important projects and goals.
Automated PDF data extraction can be particularly useful in a range of situations. For example, if you work in finance or accounting, you may need to regularly extract data from hundreds or thousands of invoices or receipts. Automating this process can help you to save time and reduce errors, improving the efficiency of your operations.
Similarly, if you work in marketing or sales, you may need to extract data from customer feedback forms, surveys, or other documents. Automating this process can help you to analyze this data more quickly and effectively, allowing you to identify trends, insights, and opportunities for improvement.
Automating PDF data extraction can be a valuable tool for anyone who needs to extract data from PDFs regularly. Whether you're a small business owner, a freelancer, or a large corporation, automation can help you improve your workflow, save time, and achieve better results.
How to Get Automated Data Extraction from PDF
Now that we've explored the benefits of automating PDF data extraction, let's look at how you can start this process. In this section, we'll walk through the step-by-step process of using automated data extraction from a PDF tool.
Method 1: Use PDFelement Automatic Data Extraction Tool
Wondershare PDFelement - PDF Editor Wondershare PDFelement Wondershare PDFelement is a popular PDF editor with advanced features, including an automatic data extraction tool. This tool allows you to extract data from PDFs automatically, using customizable templates that can recognize and extract specific data types, such as names, addresses, and phone numbers.


 G2 Rating: 4.5/5 |
G2 Rating: 4.5/5 | 100% Secure
100% Secure
To use the automatic data extraction tool in PDFelement, follow these steps:
Extract Data from PDF Form Fields
This process is suitable if the PDF file is a fillable form.
Step 1 Launch PDFelement and click "Form."
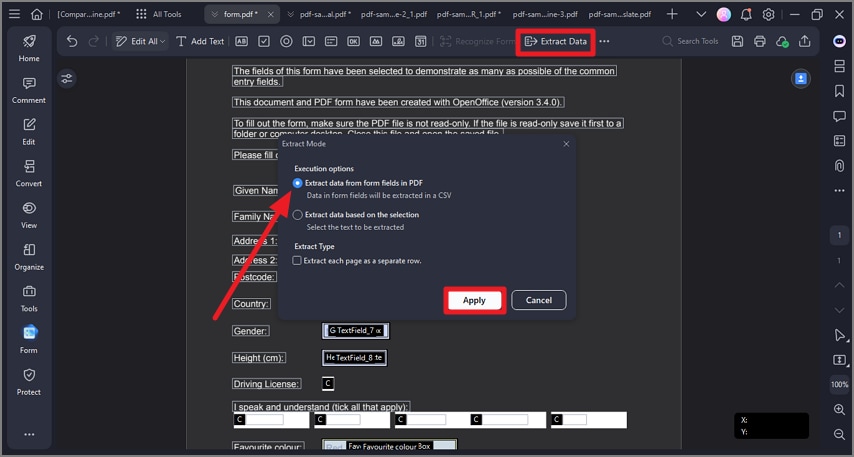
Step 2 Click the "Extract Data" option.
Step 3 Select "Extract data from form fields in PDF."
Step 4 Click the "Apply" button.
Extract Data from Selected PDF Test
If your PDF file is not a fillable form, you can extract data from the marked areas of the PDF file.
G2 Rating: 4.5/5 |100% Secure
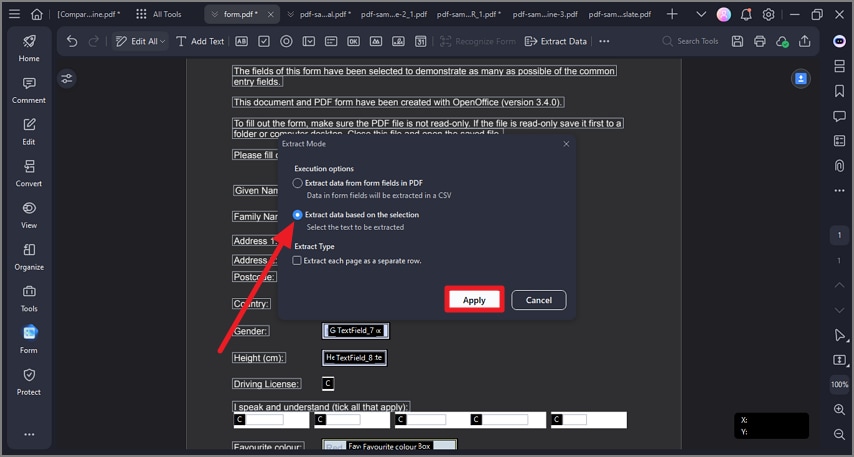
Step 1 Launch PDFelement and click "Form" > "Extract Data" > "Extract data based on selection" > "Apply" button.
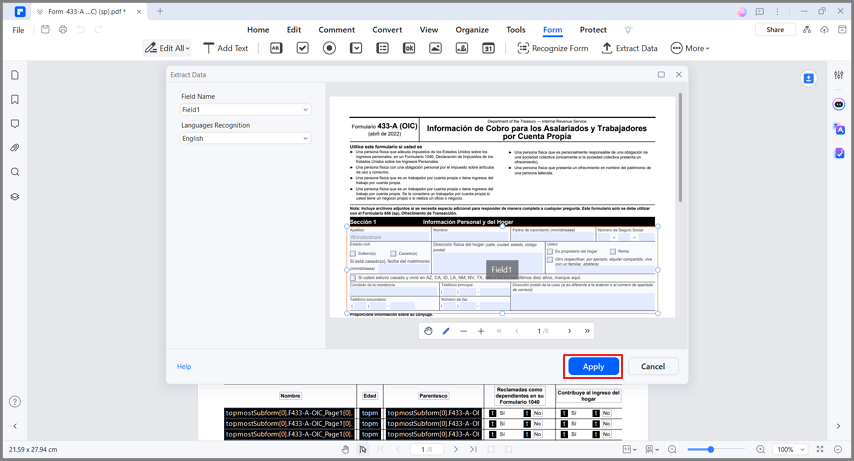
Step 2 Select the area on the page that you want to extract. Set the language in the "Language Recognition" tab and click "Apply."
Extract Data for Batch Process
You can use the Batch Process tool if you have multiple PDFs that you want to extract the data.
G2 Rating: 4.5/5 |100% Secure
Step 1 Launch PDFelement and click "Tool" > "Batch Process" > "Extract Data" button.
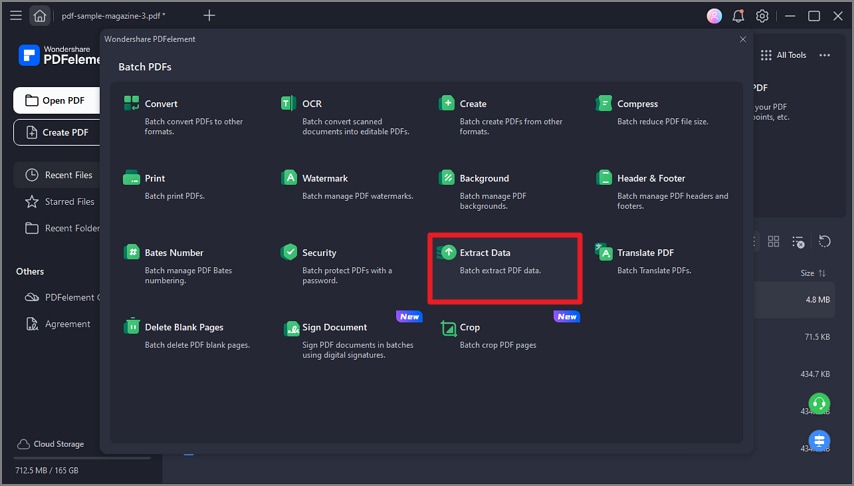
Step 2 Import the PDFs and select the location to save the extracted file. Click the "Apply" button to extract the data.
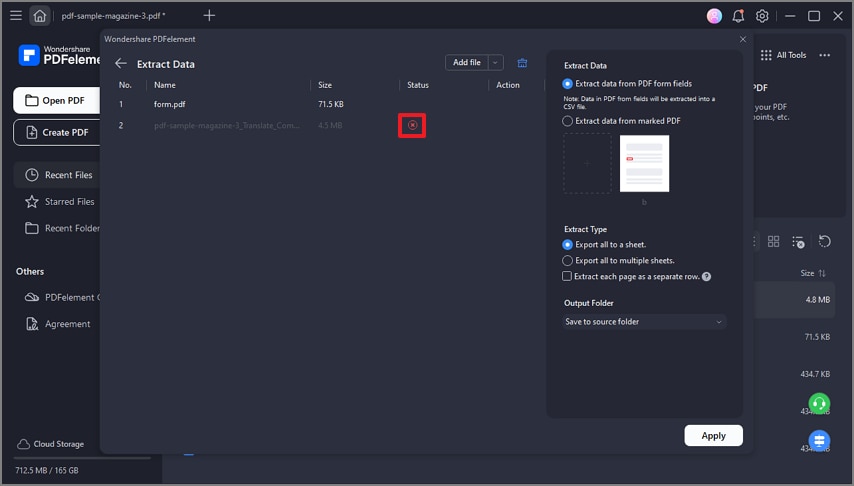
Once you've selected your template, PDFelement will automatically scan the PDF document for relevant data and extract it into a spreadsheet or other format that you can use for further analysis. You can also customize your template to extract specific data or information from your PDF documents, making this method highly flexible and customizable.
This method can be particularly useful when extracting data from large volumes of PDF documents, such as financial reports, invoices, or customer feedback forms. By automating the data extraction process, you can significantly reduce the time and effort required to extract data from these documents while also improving the accuracy and consistency of your data.
Method 2: Convert PDF to Excel With PDFelement
Converting PDF to Excel is another powerful method for extracting data from PDF documents. This method involves using PDFelement to convert your PDF file to an Excel spreadsheet, which can be easily manipulated and analyzed using Excel's advanced data processing tools.
Here's how to do it:
G2 Rating: 4.5/5 |100% Secure
Step 1 Launch PDFelement and import the PDF file.
Step 2 Click the "Convert" > "To Excel."
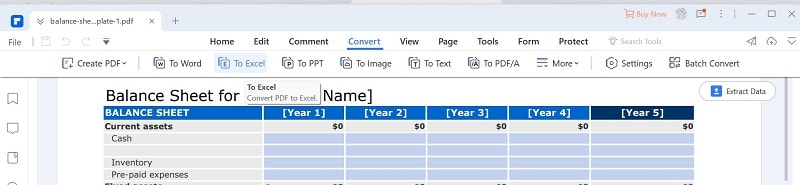
Step 3 Save the Excel. The PDF file will be converted to Excel. Once done, designate a target folder for saving the resulting Excel file.
The main benefit of converting PDF to Excel for data extraction is flexibility. With Excel, you can easily sort, filter, and analyze your data in a way impossible with a PDF document. Additionally, Excel allows you to create graphs and charts to visualize your data, making it easier to identify trends and patterns.
This method can be particularly useful when extracting data from tables or other structured data within a PDF document. For example, suppose you have a large financial report that contains multiple tables. Converting the PDF to Excel allows you to easily extract and analyze the data in each table separately.
Another situation where converting PDF to Excel can be useful is combining data from multiple PDF documents into a single spreadsheet. By converting each PDF to Excel and merging the resulting spreadsheets, you can quickly and easily consolidate your data for further analysis.
Method 3: Use Codes & Scripts
Using codes and scripts for automated PDF data extraction is a highly customizable and flexible method that allows you to extract data from PDF documents using programming languages like Python, Java, or Ruby. This method provides several benefits, including the ability to handle large volumes of data and the ability to customize the extraction process to meet your specific needs.
The basic steps for using codes and scripts to extract data from PDF automatically involve using a PDF library or module to read the PDF document and extract the relevant data. For example, you can use the PyPDF2 library in Python to extract text and data from PDF documents. Here's an example code snippet that demonstrates how to use PyPDF2 to extract data from a PDF document:
import PyPDF2
pdf_file = open('example.pdf', 'rb')
pdf_reader = PyPDF2.PdfFileReader(pdf_file)
page = pdf_reader.getPage(0)
text = page.extractText()
print(text)
In this example, we're opening a PDF document called "example.pdf" and using PyPDF2 to extract the text from the document's first page. We can then manipulate this text to extract the specific data we're interested in.
This method can be particularly useful when you need to extract data from complex or non-standard PDF documents or when you need to process large volumes of PDFs automatically. For example, suppose you're a data analyst working with financial reports or invoices. In that case, you can use codes and scripts to extract specific data types from these documents automatically and save significant time and effort.
Comparison of Methods
Regarding automating PDF data extraction, several methods are available, each with advantages and disadvantages. Here's a comparison table that highlights the key features of each method:
Method |
Advantages |
Disadvantages |
| PDFelement Automatic Data Extraction | Easy to use, no programming knowledge required | Limited flexibility, may not work for all PDF documents |
| Convert PDF to Excel with PDFelement | Provides flexibility and advanced data processing tools | May not work for all PDF documents, requires some Excel knowledge |
| Use Codes & Scripts | Highly customizable, can handle large volumes of data | Requires programming knowledge, may be time-consuming to set up |
As you can see, each method has its strengths and weaknesses, and the best method for you will depend on your specific needs and expertise. If you're looking for a simple, easy-to-use solution, PDFelement Automatic Data Extraction may be your best choice. However, converting PDF to Excel with PDFelement may be better if you need more flexibility and advanced data processing tools.
If you have programming knowledge and need to handle large volumes of data, using codes and scripts may be your most effective method. However, this method requires more setup time and expertise than the other methods, so there may be better choices for some.
Conclusion
Automating PDF data extraction can save you time and increase accuracy in your data analysis. Among the methods presented, PDFelement is a powerful automatic data extraction and conversion tool. With its user-friendly interface and advanced data processing tools, PDFelement can help you streamline your workflow and improve your productivity.

