
Using Linux optical character recognition (OCR) software is a smart move for people and companies needing to encode vast amounts of scanned or PDF documents.
The software makes life easier if you wish to go paperless. It allows you to make your non-editable files "readable" by your device. Moreover, it gives you the power to quickly extract text from your images.
There are tons of this type of application out there. This article is for you if you have difficulty choosing what's best to extract text from your images or PDFs.
In this article
List of Best OCR Software
Finding OCR software for Linux can be challenging. Unlike Mac or Windows, this operating system has limited users, often in the tech industry. Because of their small number, you can find fewer apps of this nature developed for this system. Here are some of them.
Tesseract
If you love free and open-source software, Tesseract should be one of your top choices. Even though you don't need a penny to install this application on your Linux, it can give you great results. It is because Google developed and provided the engine for this app. This software can greatly benefit the tech giant's capabilities and resources.

Tesseract is a powerful character recognition tool. It can easily convert sections of your books, PDFs, archives, and other types of texts. It can also detect the characters from documents with tiny font sizes and where the text is hard to read.
Tesseract can even restore the types and sizes of fonts according to the original with minimal error. Moreover, it supports more than 100 global languages like Chinese, Spanish, Arabic, and regional languages like Gujarati, German Fraktur, and Cebuano.
To use this PDF OCR software in Ubuntu, select the file you want to process.
Then on the tesseract command prompt, give the information about the file, including:
- The name of the file that you wish to process.
- The name of the file that your system will create to contain the extracted text - It will always be saved as .txt, so there's no need to provide the file extension.
- You can also use the --dpi option to notify Tesseract of the resolution of the image in the dots per inch (dpi). If you don't specify the dpi value, Tesseract will figure it out.
For example, if the file is img.png, the command could look like this:
The output, by default, will be img.txt.
gImageReader
Another popular OCR software in Linux is gImageReader. This application can do many features, including extracting text from multiple files and checking spelling. It can also perform post-processing on machine-readable text.
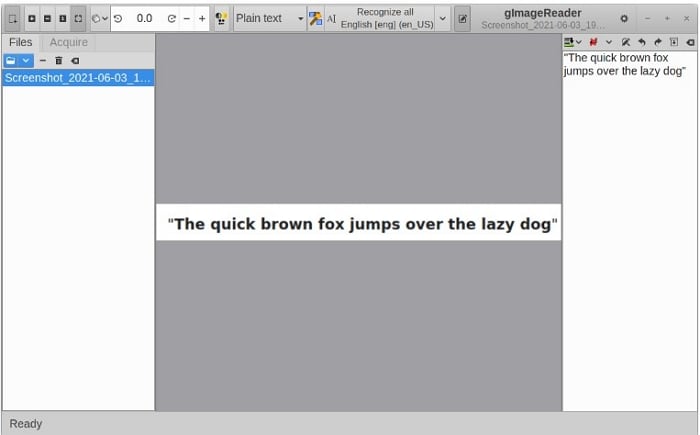
Let gImageReader perform its OCR task by doing the following steps:
Step 1 Click Add Images in the left section under the toolbar and select the image or PDF you want to process.
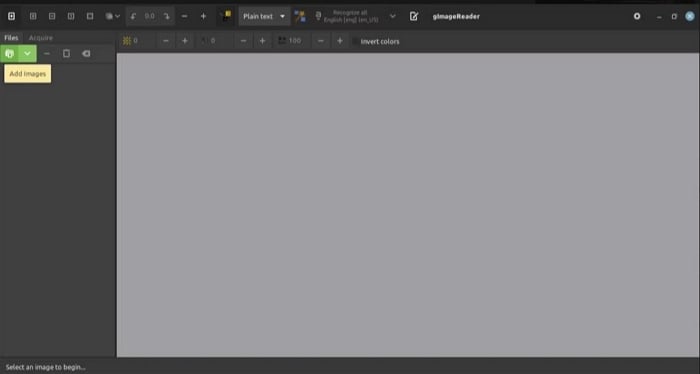
Step 2 Click Ok to import the image or PDF to the software.
Step 3 You can also have the option to extract text from the file displayed on the screen. Hit the dropdown next to Add Images and select Take Screenshot. gImageReader will take a screenshot of the content on the screen.
Step 4 Once you've loaded the image to gImageReader, click the Toggle output pane (one with the notepad icon) to open the output pane. Doing this will allow the text you extract from images or PDFs to show up.
Step 5 You now have the option to detect the text in the file automatically or manually.
Step 6 If you choose automatic identification, click on the Autodetect layout button highlighting all the text blocks in the selected document.
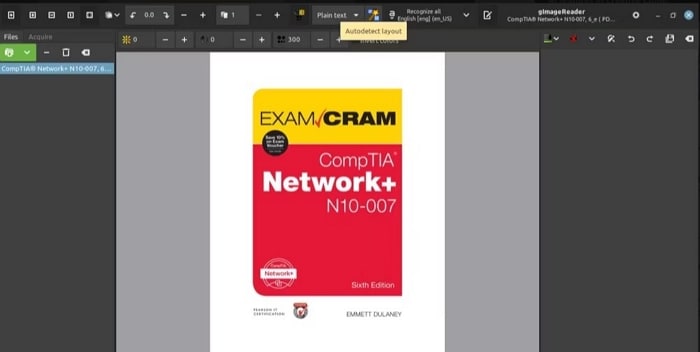
Step 7 Choose Recognize selection > Current Page to start the text extraction.
Step 8 If you prefer manual text selection, place the mouse pointer over the text you want to extract. Then click the Recognize selection button to start the process.
OCRFeeder
Another free and open-source OCR for Linux out there is OCRFeeder. The developers intended this application to be exclusive to Linux users. At present, the GNOME team maintains this software.
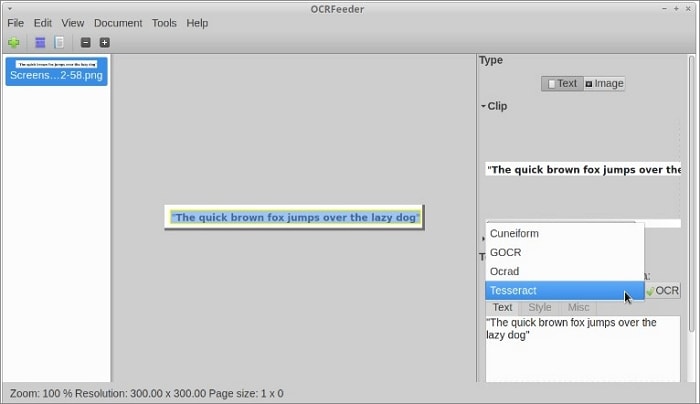
OCRFeeder looks for content areas and outlines them to detect the content type, whether text or image. Then it processes text areas using the OCR back-end.
This application can use almost all command-line OCR engines, including Tesseract, to perform. It also has auto-detection and auto-configuration features for all well-known free engines. Follow this procedure to use OCRFeeder:
Step 1 Open the software.
Step 2 Import an image that you want to extract the text. You can also import the folder containing the files you intend to process.
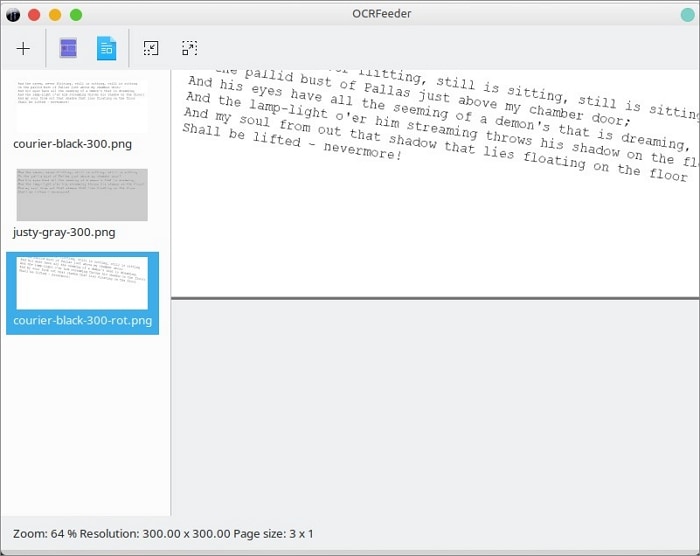
Step 3 Hit Identify Document. Once you've identified the document, you can manually select the parts you want to extract.
Step 4 Before exporting the document, choose Edit > Edit Page to select the desired page.
Step 5 Export the document by choosing File > Export. Then, select the desired output format, preferably .txt format.
FuzzyOCR
FuzzyOCR is a plugin for SpamAssassin, an anti-spam platform that inspects various image files found in emails to determine if they are spam. This application reads the images attached to the email. It then decides if they're spam or not based on a list of words.

Once this OCR software is installed and configured, it can perform its image detection. Find out the procedure for how to make this application work:
Step 1 After downloading, unpack FuzzyOCR and move the entire FuzzyOCR* files and the FuzzyOCR directory.
Step 2 Configure it to make it work using SpamAssassin by opening open the filename /etc/mail/spamassassin/FuzzyOCR.cf, then make some changes:

Step 3 Once the FuzzyOCR is configured, you can feed each email to SpamAssassin to see if the plugin is linked correctly to the software. Here is an example:
SpamAssassin can now recognize image spam using FuzzyOCR
Benefits and Limitations of Linux OCR
Any Linux OCR software brings many advantages. Thanks to the growth in technology, these applications have become more and more reliable. They are must-haves for people and businesses that need fast and accurate text extraction toward a paperless living.
Benefits
Higher productivity - Instead of encoding yourself or delegating it to someone else, you can run this software and let it do its thing. You can start converting text while doing your usual work simultaneously.
Lower cost - This technology is cheaper than paying someone to enter a massive chunk of text data manually. Making PDF text and images machine-readable takes less energy and resources.
High accuracy - These applications allow captured information to be readable. Flatbed scanners and the latest digital cameras produce high-resolution images enabling these applications to detect text.
Increased storage space - Storing scanned image files, especially high-resolution ones, requires considerable space in your hard disk. Turning them into machine-editable documents would give your drive plenty of room to store other, more important files.
Superior data security - Lost or scanned paper documents can be a security nightmare. Mishandling the file can make it prone to tampering. You can store documents without signatures and seals if you can convert and store them in an editable file.
Limitations
Difficulty recognizing handwritten text - These apps work efficiently with printed text but have problems reading handwritten ones. Like in the case of humans, some handwritings are hard to read.
May need technical people to install - You may need a few people with advanced tech skills to install Linux OCR software for PDFs and other files. Unlike Windows or Mac, only a tiny fraction of people know to use this operating system.
Still requires tons of editing - While modern OCR software has high accuracy, they are still prone to errors. You still need to check the documents carefully and manually correct them to ensure they are error-free.
The recognition accuracy depends on the quality of the image.
Best OCR Tool for Windows, Mac, and iOS
Character recognition applications are not limited to Linux users. Windows and Mac users can also choose from a wide variety of text-extracting software. Among the available software, PDFelement is your intelligent choice with its leading features.
Wondershare PDFelement - PDF Editor Wondershare PDFelement Wondershare PDFelement has a full range of functionality that make text extraction a user-friendly experience. The software will perform its task accurately by uploading PDF or other image formats.
Besides OCR, it has a wealth of functionalities that can streamline your work. After making the text editable, you can make revisions and convert the files into PDF, Word, Excel, and PowerPoint. You can make it an eBook by exporting it into EPUB format or a webpage by making it an HTML file.


 G2 Rating: 4.5/5 |
G2 Rating: 4.5/5 | 100% Secure
100% Secure
Here are the steps on how to install this software and use it as an OCR tool on Windows:
Step 1 Download and install PDFelement from its website.
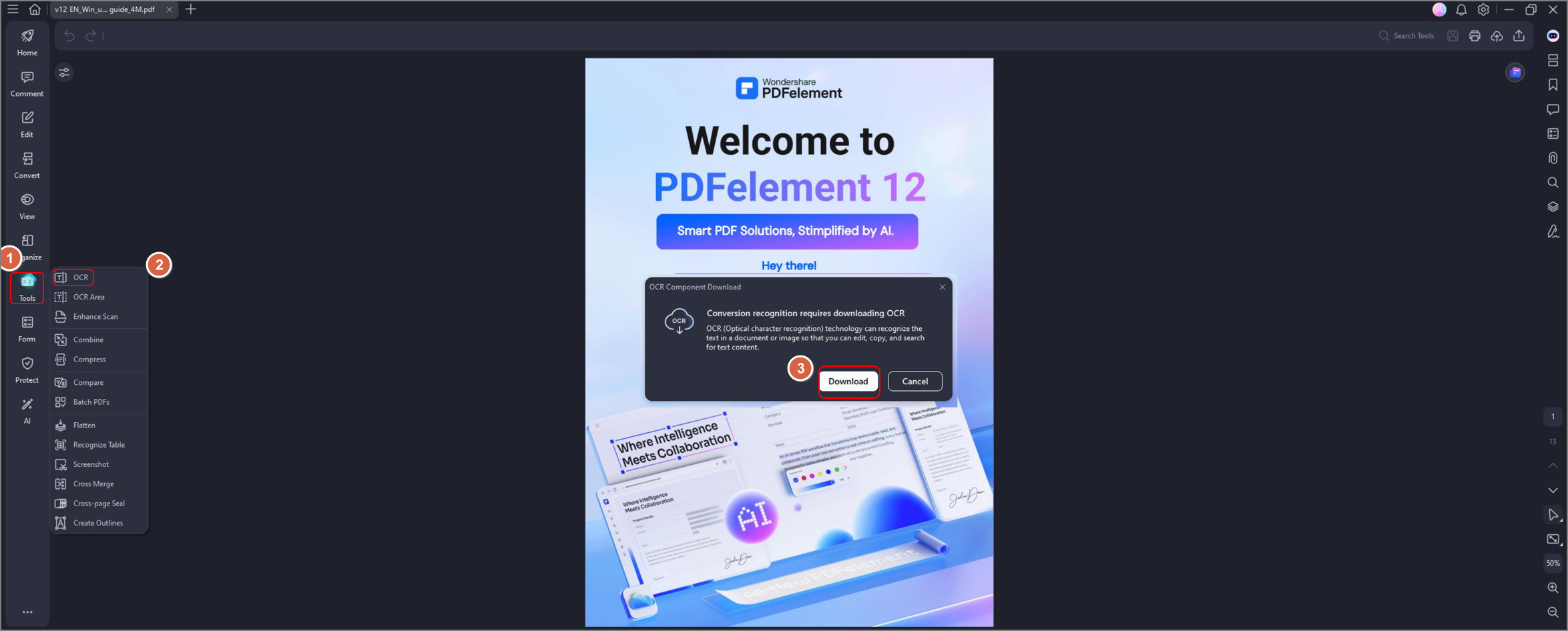
Step 2 Open a PDF file and hit the OCR on the secondary navigation button to use the OCR function. A pop-up window will appear asking if you want to download the extra feature. Click Download and complete the installation.
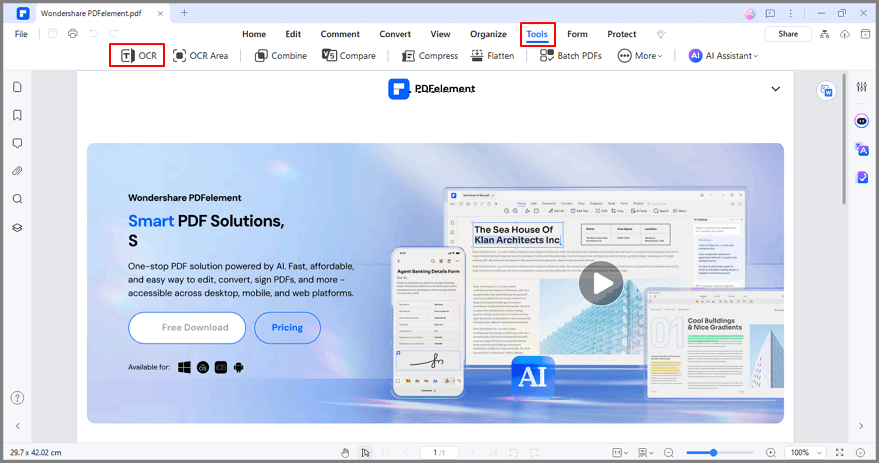
Step 3 Once the installation is complete, you can convert the document into a text file. Click on the OCR button, which will lead you to this selection:
Step 4 Once you finish the PDF document extraction, choose the format you want your document to be converted into.
G2 Rating: 4.5/5 |100% Secure
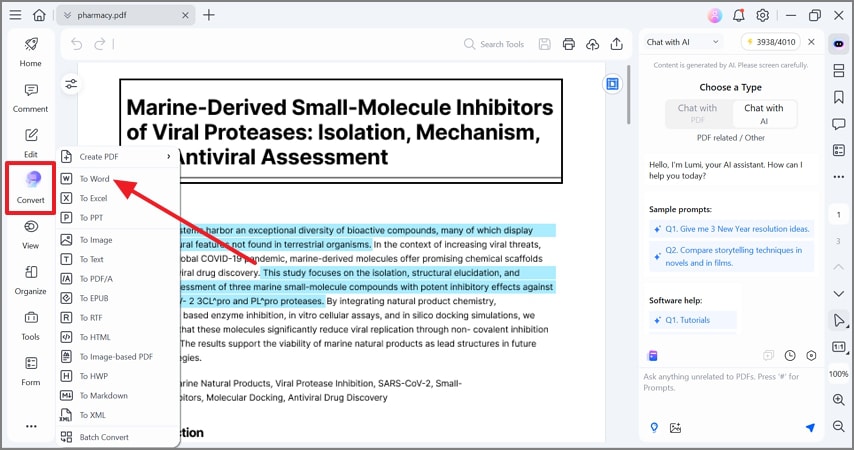
If you use the free trial version, you can use the OCR feature for a limited number of conversions and functionalities. You may want to pay for its Pro version to get the most from this application.
Aside from desktops, mobile users can also install this software on their devices. Users can also use this application on the cloud.
Conclusion
For people and businesses who often work with documents of any form, OCRs for PDF and image files are essential for better productivity. These apps let you extract the characters in your files and turn them into machine-readable text. If you want quality OCR software that is user-friendly and robust enough for your heavy requirements, PDFelement is your intelligent choice.

