
In this article
- Can LibreOffice Natively Perform OCR?
- Method 1: Using LibreOffice with Free Online OCR Tools
- Method 2: Exploring the LibreOCR Extension
- Limitations of LibreOffice OCR Workarounds
- Method 3: The Best Dedicated Alternative – Wondershare PDFelement
- How to Perform OCR with PDFelement (Step-by-Step)
- Advantages of Using PDFelement Over LibreOffice for OCR
- Comparison: LibreOffice vs. PDFelement OCR Capabilities
- Best Practices for High-Quality OCR Results
- Conclusion
LibreOffice is universally recognized as one of the most powerful free and open-source office suites available today. Millions of users rely on its suite of applications—Writer, Calc, Impress, and Draw—for daily document management. However, when it comes to handling scanned documents, users frequently run into a common roadblock: Optical Character Recognition (OCR).
If you are trying to edit a scanned document, you are likely looking for a reliable LibreOffice OCR solution. OCR is the critical technology that turns an image of text (like a scanned paper or photograph) into machine-readable, editable text. Without it, a scanned PDF is essentially just a locked image.
In this comprehensive guide, we will explore exactly how you can extract text from images using LibreOffice, discuss popular extensions like LibreOCR, and introduce dedicated alternative workflows to make your document management effortless.


 G2 Rating: 4.5/5 |
G2 Rating: 4.5/5 | 100% Secure
100% Secure
Can LibreOffice Natively Perform OCR?
The short answer is: No, LibreOffice does not have a native, built-in OCR engine.
When you open a digital, text-based PDF in LibreOffice Draw, the software can usually identify the text blocks, allowing for basic edits. However, if you open a scanned PDF, LibreOffice Draw will simply treat the entire page as a single image file. You can resize or move the image, but you cannot click into the text to change words, delete sentences, or alter the font.
Because it is open-source, the community has developed various workarounds to bridge this gap. To achieve libreoffice ocr pdf capabilities, you essentially have two main choices:
- Use an external tool (like a web app) to convert the document before bringing it into LibreOffice.
- Rely on an open-source extension, though these can be highly technical to configure.
Method 1: Using LibreOffice with Free Online OCR Tools
The most common and user-friendly workaround for users who want to stick strictly to LibreOffice for their final editing is a hybrid approach. This involves using a free online OCR service to do the heavy lifting, and then using LibreOffice Writer to format and finalize the document.
Here is the step-by-step workflow:
Step 1Open Your Document
Start by opening LibreOffice. Click on "File" in the top menu, select "Open," and locate your PDF file. If it is a scanned document, Draw will display the PDF content as a flat image. This confirms that OCR is necessary.


Step 2Utilize an External OCR Service
Since LibreOffice lacks the OCR feature, you must step outside the program temporarily. Find a reputable free online OCR service. Upload your scanned PDF to the service. The cloud-based tool will process the images and extract the text.

Step 3Import into LibreOffice Writer
Once the online service finishes its process, download the resulting text file (usually a .txt or .docx file). Return to LibreOffice, open LibreOffice Writer, click "File," and select "Open."

Locate the text file you just downloaded and open it. You will now see the raw text extracted from your scan.

Step 4Edit and Save
You can now edit the text, change fonts, add formatting, and reconstruct the document layout. Once you are satisfied with the edits, it is highly recommended to save your work as an ODT file (the native LibreOffice format) for future edits.
Finally, to share the document, you can export it back to a PDF. Click "File" > "Export" > "Export as PDF." Selecting "Hybrid PDF" is a great option here, as it embeds the ODT file within the PDF, making future editing in LibreOffice much easier.

Method 2: Exploring the LibreOCR Extension
For users who want everything integrated into their desktop environment without relying on the cloud, the open-source community has developed extensions. The most notable in discussions is LibreOCR.
What is LibreOCR?
LibreOCR is an extension designed to bring OCR capabilities directly into the LibreOffice interface. It does not reinvent the wheel; instead, it acts as a graphical user interface (GUI) wrapper for Tesseract, one of the most powerful open-source OCR engines originally developed by HP and later maintained by Google.
How it Works
When successfully installed, users can theoretically trigger a macro or extension button that sends the image data to Tesseract, which processes the text and feeds it back into the LibreOffice document.
The Catch
While the idea of a libreocr extension sounds perfect, the reality is often complicated. Installing Tesseract requires command-line knowledge on some operating systems. Furthermore, integrating it with LibreOffice often requires installing specific Python scripts, configuring system path variables, and dealing with version compatibility issues. For the average user simply looking to edit a PDF, this method is usually too complex and prone to breaking during software updates.
Limitations of LibreOffice OCR Workarounds
Whether you use an online tool or attempt to configure a Tesseract extension, relying on LibreOffice for OCR comes with distinct disadvantages:
- Formatting Loss: External text extractors usually strip away formatting. You might get the words right, but tables, columns, headers, and bullet points are often destroyed, requiring hours of manual reconstruction in LibreOffice Writer.
- Security Risks: Uploading sensitive business documents, medical records, or personal files to free online OCR websites poses a significant data privacy risk.
- Multi-Language Barriers: Handling documents with mixed languages or complex character sets (like Asian languages or Arabic) often causes free tools to produce gibberish.
Method 3: The Best Dedicated Alternative – Wondershare PDFelement
If your primary goal is to edit scanned PDFs quickly, accurately, and securely, bypassing the LibreOffice workarounds for a dedicated tool is the most logical choice. Wondershare PDFelement is a professional PDF editor equipped with a highly advanced, built-in OCR engine.
Unlike the fragmented LibreOffice workflow, PDFelement handles everything in one place. It uses Artificial Intelligence to analyze scanned documents, recognize text (even in poor-quality scans), and seamlessly overlay editable text exactly where the original image text was. This preserves the document's original layout, fonts, and formatting.
G2 Rating: 4.5/5 |100% Secure
How to Perform OCR with PDFelement (Step-by-Step)
Using PDFelement to perform OCR is incredibly straightforward. Here is how you can transform a scanned document into a fully editable file in minutes:
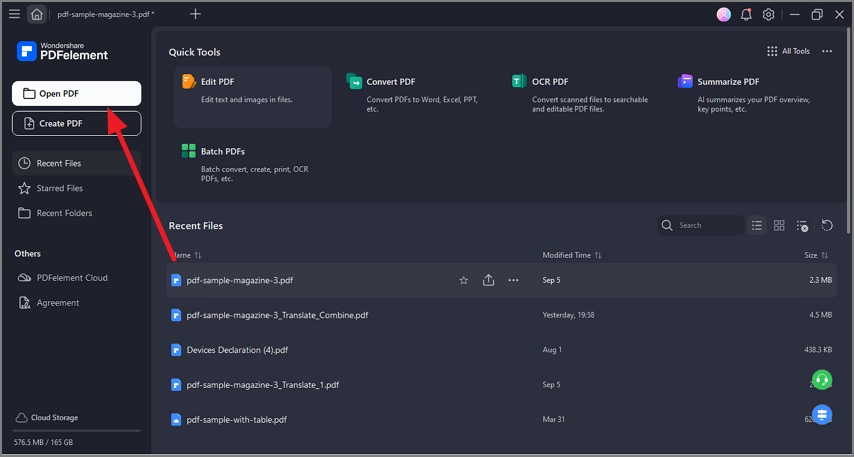
Step 1Open the File
Launch PDFelement and load your scanned PDF file by clicking on the 'Open File' button on the home screen.
Step 2Access the OCR Tool
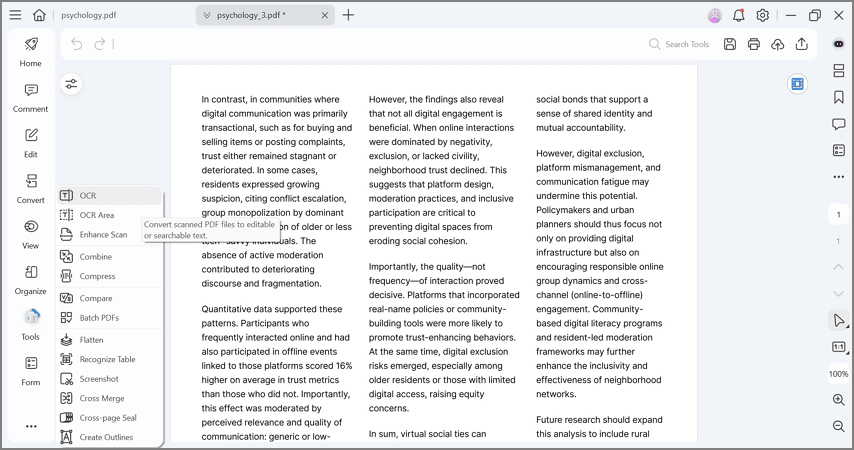
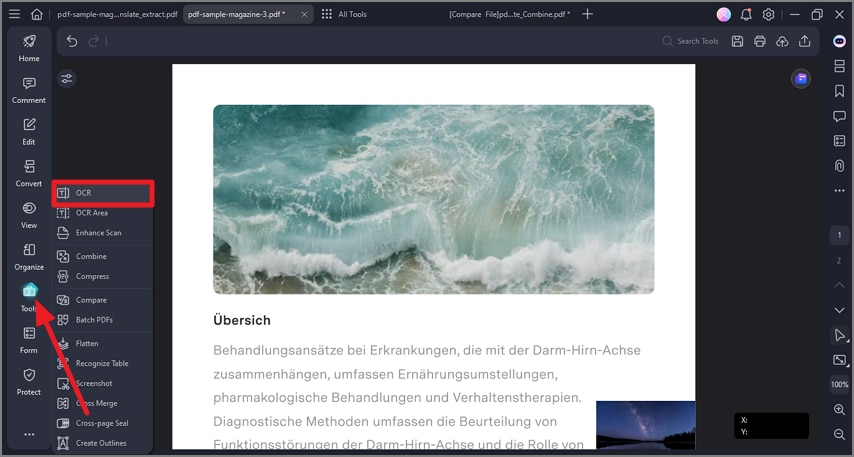
Because PDFelement detects that the file is a scan, it will often prompt you automatically. Alternatively, you can click the "Tools" tab in the top menu and select the "OCR" button.
Step 3Choose Scan Options
A configuration window will appear. Select "Scan to editable text". This ensures that the recognized text can be altered, deleted, or added to, rather than just made searchable.
G2 Rating: 4.5/5 |100% Secure
Step 4Select the Language
For maximum accuracy, click "Change Language" and select the language(s) present in your document. PDFelement’s robust engine supports over 20 languages, making it ideal for international documents.
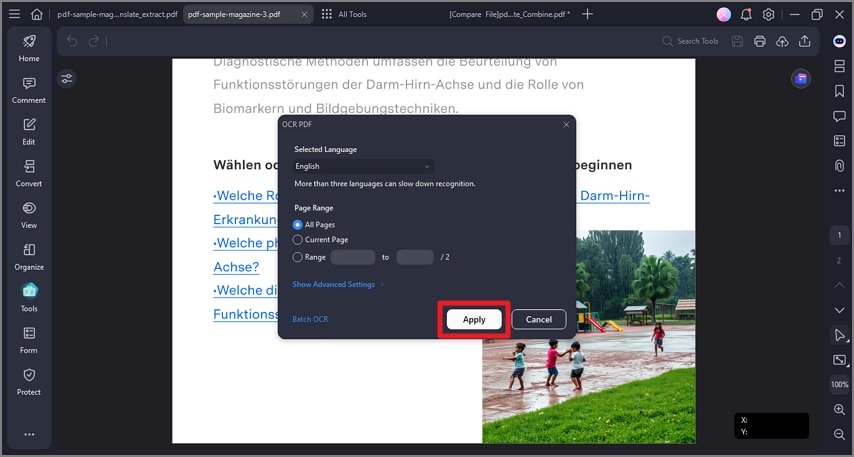
Step 5Apply OCR
If you only need a specific section, you can select a page range. Otherwise, click "Apply" to begin. A progress bar will track the AI's real-time processing.
Step 6Edit the Document
Once complete, the document transforms. You can now click the "Edit" button and click directly onto the text. You can fix typos, change numbers, or update paragraphs just like you would in a standard word processor, with the layout remaining perfectly intact.
Advantages of Using PDFelement Over LibreOffice for OCR
While LibreOffice is exceptional for generating new documents from scratch, PDFelement is purpose-built for managing existing PDFs.
- Flawless Layout Retention: PDFelement respects the visual integrity of your document. Images stay where they belong, and text boxes remain aligned.
- AI-Powered Accuracy: The AI engine handles skewed scans, low-contrast text, and strange fonts significantly better than free online tools.
- Offline Security: All OCR processing happens locally on your machine, ensuring your sensitive data never touches a public cloud server.
- Complete PDF Toolkit: Beyond OCR, PDFelement allows you to merge files, digitally sign contracts, redact sensitive info, and convert PDFs to Excel, Word, or PowerPoint formats effortlessly.
Comparison: LibreOffice vs. PDFelement OCR Capabilities
| Feature/Metric | LibreOffice (with workarounds) | Wondershare PDFelement |
|---|---|---|
| Native OCR Built-in | No (Requires external tools/extensions) | Yes (AI-powered built-in engine) |
| Layout Preservation | Very Poor (Text is extracted raw) | Excellent (Maintains exact layout) |
| Ease of Use | Complex (Requires switching apps) | Very Easy (One-click processing) |
| Data Privacy | Low (If using free web tools) | High (Processed locally) |
| Supported Languages | Varies based on third-party tool | 20+ Languages supported natively |
| Best Used For | Free, casual text extraction | Professional, accurate PDF editing |
G2 Rating: 4.5/5 |100% Secure
Best Practices for High-Quality OCR Results
Regardless of whether you use a LibreOffice extension or a premium tool like PDFelement, the quality of your OCR output depends heavily on the quality of the input. Follow these tips to ensure the best results:
- Optimal Resolution: Ensure your scanner is set to at least 300 DPI (Dots Per Inch). Anything lower may result in blurry text that software struggles to read.
- Proper Lighting and Contrast: If you are taking a photo of a document with your phone, ensure there are no shadows cast across the page and that the text sharply contrasts with the paper.
- Keep it Straight: Skewed or tilted text reduces recognition accuracy. While tools like PDFelement auto-deskew pages, providing a straight scan yields faster, more accurate results.
Conclusion
Tackling a libreoffice ocr pdf task requires an understanding of what LibreOffice can and cannot do. Because LibreOffice lacks a native OCR engine, users must rely on external online converters or complex extensions like libreocr to extract text. While these methods are free, they often result in lost formatting, wasted time, and potential privacy risks.
For users who frequently deal with scanned documents, investing in a dedicated PDF editor like Wondershare PDFelement is the smartest choice. With its AI-powered OCR, intuitive interface, and ability to preserve original document layouts, PDFelement transforms the frustrating task of manual data entry into a seamless, one-click process. Choose the tool that best aligns with your workflow, technical comfort, and document management needs.
People Also Ask
-
Can LibreOffice OCR handwritten notes?
No, LibreOffice cannot OCR handwritten notes. Furthermore, standard OCR tools often struggle with handwriting. You will need specialized Intelligent Character Recognition (ICR) software or advanced AI tools like PDFelement to accurately transcribe handwriting, which can then be exported as text and pasted into LibreOffice. -
Is OCR in LibreOffice free?
Because LibreOffice itself does not feature native OCR, the cost depends on the workaround you use. Utilizing free online OCR services or installing open-source engines like Tesseract is free but costs time in manual corrections. Dedicated, high-accuracy tools usually require a license or subscription. -
How do I install the LibreOCR extension?
Installing LibreOCR generally involves downloading the extension file (.oxt) from the LibreOffice extensions repository, opening LibreOffice, navigating to Extension Manager, and adding the file. However, you must also install Tesseract on your operating system and configure the system paths correctly for the extension to function. -
Why is my OCR text full of spelling errors?
This usually happens when the source image is of poor quality (low DPI, blurry, or poor contrast) or the wrong language was selected in the OCR settings. Ensure your scans are clear and utilize high-quality OCR engines like PDFelement to minimize recognition errors.

