
PDF files are common for invoices, reports, and statements across everyday business tasks. However, copying tables by hand is slow and introduces avoidable typing mistakes. Therefore, accurate conversion matters when totals, dates, and columns must stay consistent.
Many teams ask how to unlock structured values without damaging layout or formulas. That is why how to extract data from PDF into Excel remains a frequent operational need. Moreover, scanned documents add noise, skew, and faint ink that complicate extraction accuracy. Consequently, choosing the right method can protect data quality and reduce rework later.
In this article
- Why People Extract PDF data into Excel
- Why Extracting Data From PDFs into Excel is Difficult
- Choosing The Right Method to Extract PDF Data Into Excel
- Method 1: Using Excel's Built-In "Get Data from PDF" Feature
- Method 2: Copying Data From PDF to Excel
- Method 3: Converting PDF Data to Excel with PDF Software
- Method 4: Extracting Data From Scanned PDFs into Excel
- Extracting PDF Data into Excel with PDFelement
- Improving Excel Results After Extraction
- Free and Online PDF-to-Excel Methods: What To Expect
- Common Mistakes When Extracting PDF Data into Excel
Part 1. Why People Extract PDF data into Excel
Many PDFs contain valuable numbers, yet they behave like locked pages instead of usable data. So, teams move information into spreadsheets to sort, filter, validate, and reuse fields faster. That is why "get data from PDF to excel" is a common request across finance, research, and operations.
Common Use Cases for PDF Data in Excel
After converting PDF data to Excel, these practical use cases mentioned below become possible immediately:

- Data Analysis: Analysts convert PDF data to Excel to run pivots, trends, and comparisons across periods. This is common for sales summaries, survey tables, inventory lists, and performance dashboards.
- Reporting: Teams pull tables from PDFs to refresh weekly and monthly reports without retyping values. Excel makes it easier to standardise headers, merge multiple files, and produce charts quickly.
- Calculations: Once numbers are in cells, users can apply formulas, compute tax, margins, averages, and variances. This supports budgeting, reconciliation, forecasting, and quick checks on totals and subtotals.
- Data Cleanup: PDF exports often contain broken columns, extra spaces, or merged cells that need correction. Excel helps clean fields using text functions, find-and-replace, split tools, and validation rules.
Why Excel Remains the Default Analysis Tool
Excel is widely available, familiar to most teams, and flexible for both simple and advanced work. It supports structured tables, formulas, pivot tables, Power Query imports, and fast visualisation. Excel also integrates smoothly with accounting tools, CRMs, and BI platforms through exports and connectors. For many organisations, it is the quickest bridge between static documents and reliable, shareable analysis.


 G2 Rating: 4.5/5 |
G2 Rating: 4.5/5 | 100% Secure
100% Secure
Part 2. Why Extracting Data From PDFs into Excel is Difficult
Extracting data from PDFs into Excel feels simple until you see what PDFs actually store. Most PDFs prioritise visual layout, so tables look perfect while data stays unstructured underneath. A column may be text blocks, scattered spaces, and line breaks instead of true cell boundaries.
G2 Rating: 4.5/5 |100% Secure
PDF Types Behave Very Differently
Not all PDFs are built the same, so each type behaves very differently during extraction.
- Digital PDFs: These usually contain selectable text, yet tables may still be "drawn" with spacing tricks. You might get split rows, shifted columns, or merged values when exporting to Excel.
- Form-based PDFs: Forms can store data in fields, which sounds ideal, but layouts vary widely across templates. Some fields export cleanly, while others embed values as static text, complicating extraction.
- Scanned PDFs: Scans are images, not text, so extraction depends on OCR quality and image clarity. Skew, shadows, blur, and faint thermal ink can turn "8" into "0" without warning.
Why No Single Method Works For All Files
Each PDF has a different structure, fonts, compression, and table design, even within one company. A method that works on digital reports may fail on scanned invoices or complex multi-page statements. That is why reliable extraction often needs the right tool choice, plus validation checks afterward.
Part 3. Choosing The Right Method to Extract PDF Data Into Excel
Selecting the right extraction method depends on what the PDF actually contains and how you will use the results. The following quick decision framework helps you avoid wasted time, messy spreadsheets, and unreliable numbers later:
Identify the PDF Type
- Digital PDF: Text is selectable, so direct conversion or table extraction usually works best.
- Form-based PDF: Field exports can be accurate, but mixed static text may need cleanup.
- Scanned PDF: Treat it as an image, so OCR quality and preprocessing become critical first.
Check the Data Structure
- Tables: Use table-detection extraction when rows and columns repeat consistently across pages.
- Mixed Text Blocks: Use text-to-columns cleanup, or structured parsing when labels matter.
- Multi-line Cells: Expect merged values, so plan for manual review or rule-based splitting.
Consider Volume and Repetition
- One-off File: A guided conversion with manual cleanup is often fastest overall.
- Recurring Documents: Use templates, rules, or automation when layouts stay consistent monthly.
- High-volume Batches: Prioritise tools that support batch processing and standardized exports.
Define Accuracy Requirements
- Low Risk: Basic conversion may be enough for internal exploration and quick summaries.
- Medium Risk: Add validation checks on totals, dates, and key identifiers before reporting.
- High Risk: Use extraction with audit trails, dual review, and reconciliation against source totals.
Thus, use this framework as your hub to match the PDF type, structure, volume, and risk level first. Then select the method that delivers clean Excel output with the least rework and maximum confidence.
G2 Rating: 4.5/5 |100% Secure
Part 4. Method 1: Using Excel's Built-In "Get Data from PDF" Feature
Excel includes a native connector for importing table data directly from PDFs. Using Excel get data from a PDF, it scans pages and identifies likely tables. You can preview detected results before loading selected tables into worksheets safely. This approach speeds structured imports when files are clean, digital, and consistently formatted. Follow the quick workflow below to apply this method accurately in Excel:
Step 1Upon accessing the Excel, navigate to the "Data" tab and pick "Get Data from PDF" to proceed.
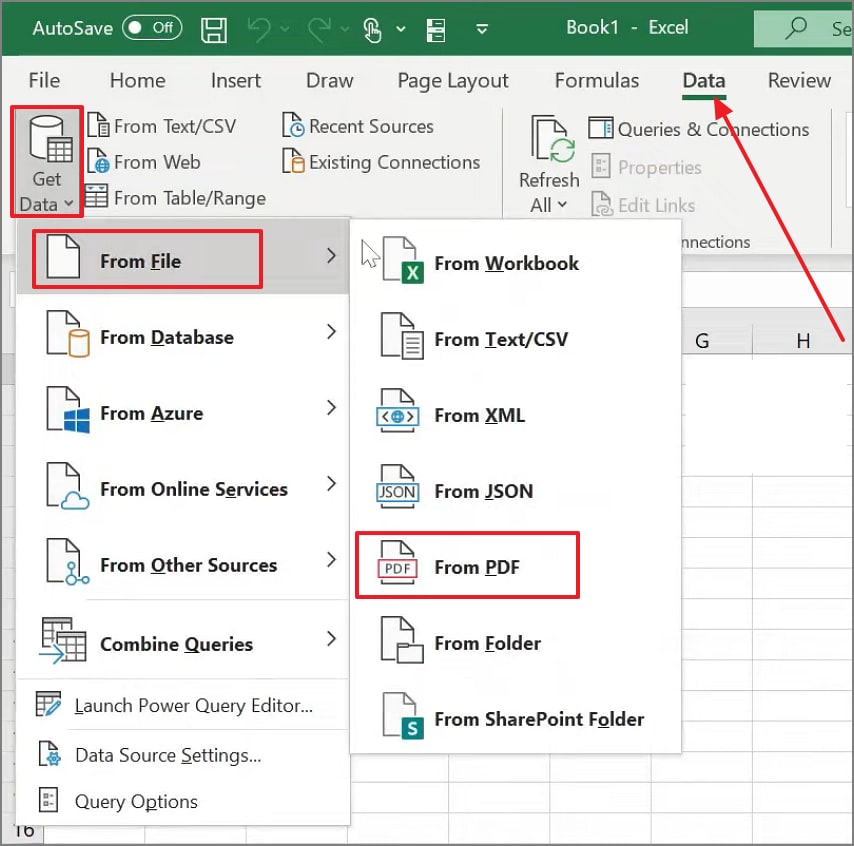
Step 2After that, browse to your file to select it, then click "Import" to continue.
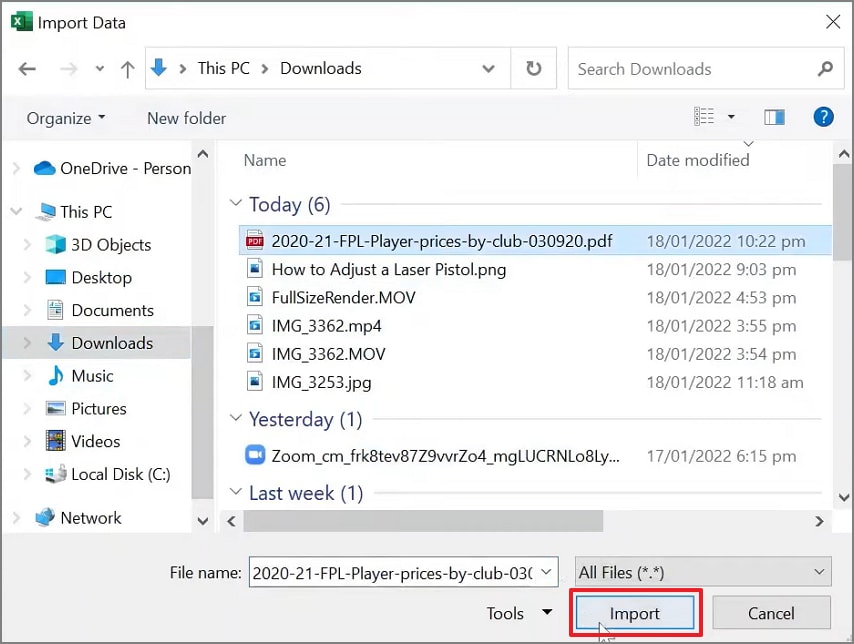
Step 3Next, click "Load" to import immediately, or choose "Transform Data" for cleanup first.
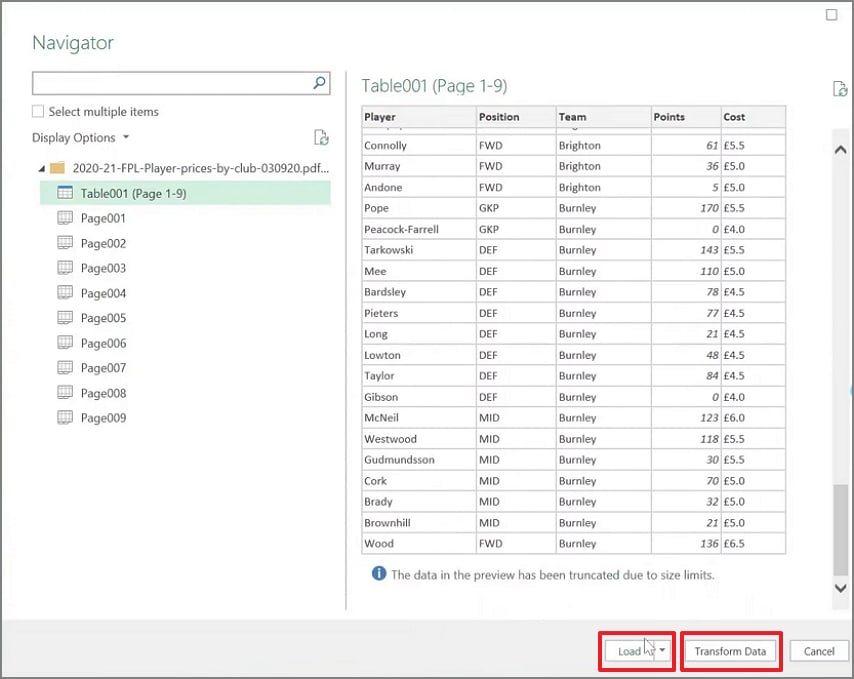
When This Method Works Well
This method works best with digital PDFs containing consistently bordered, aligned tables. Repeated invoice templates, statements, and reports usually import accurately with minimal cleanup. It supports quick reviews, calculations, and summaries when column structures remain predictable. For routine tasks, "Excel import data from PDF" reduces manual copying significantly. Thus, always verify totals and dates before using outputs in downstream reporting workflows.
Limitations of Excel PDF Import
Before relying on outputs, review these common limitations and cleanup risks carefully:
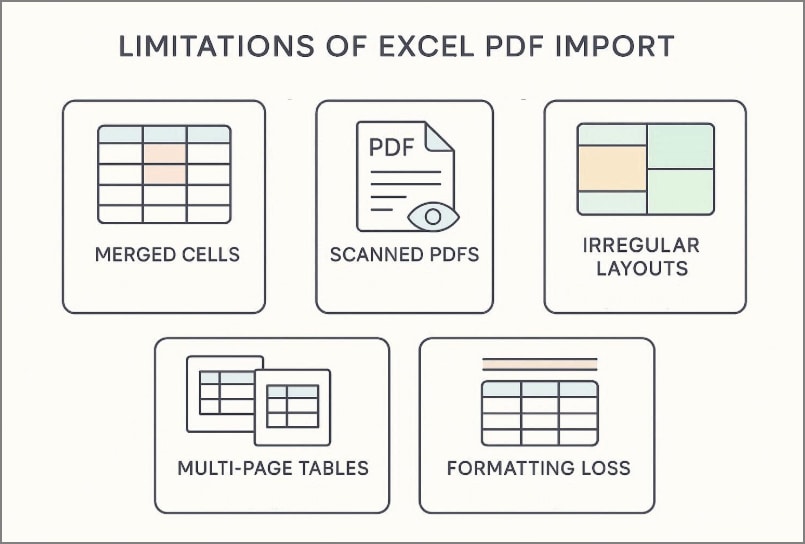
- Merged Cells: Excel may split combined headers incorrectly, shifting values across columns during import previews and loads.
- Scanned PDFs: Image-based pages need OCR first, because Excel cannot reliably detect text tables without recognition.
- Irregular Layouts: Nested headers, side notes, and spacing inconsistencies reduce table detection accuracy substantially in complex documents.
- Multi-Page Tables: Continued rows across pages often break, creating duplicates or missing values after loading data.
- Formatting Loss: Fonts, colors, merged styling, and visual cues disappear, requiring manual cleanup before reliable analysis.
Part 5. Method 2: Copying Data From PDF to Excel
Copying text directly from a PDF into Excel seems fast for small tasks. With copy data from PDF to Excel, users can paste visible values instantly. It can work for one-off tables with simple columns and clean alignment. However, pasted content often breaks structure, requiring extensive manual fixes afterward for accuracy.
When Copy-Paste Is Acceptable
Copy-paste is acceptable for one-time checks involving very small, simple tables. It works better with digital PDFs that contain clean, consistently spaced columns. Moreover, temporary comparisons, quick validations, and rough notes are suitable use cases. Always verify totals and dates before using pasted values in reports.
Common Formatting Issues
The following formatting issues often appear after pasting, even when previews initially look correct:
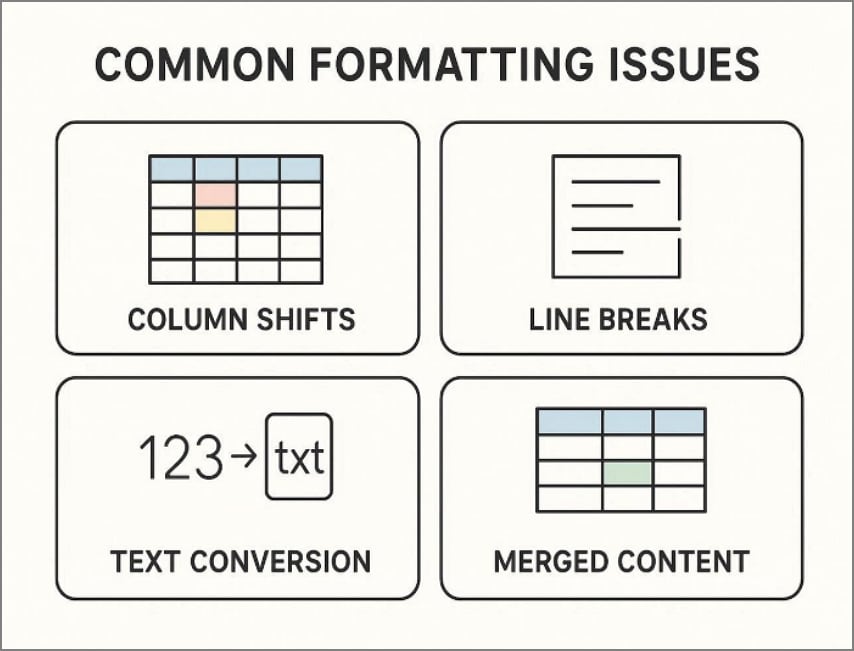
- Column Shifts: Variable spacing in PDFs pushes values into nearby columns, breaking row alignment and misplacing totals during analysis.
- Line Breaks: Hidden line breaks split single records across multiple rows, creating duplicates and disrupting formulas, filters, and sorting.
- Text Conversion: Excel often pastes dates, currencies, and percentages as text, preventing calculations until formats are manually corrected.
- Merged Content: Headers, labels, and adjacent cells paste together, causing duplicated fields, missing values, and confusing column boundaries later.
Why This Method Does Not Scale
The limitations below become worse as document volume, layout variation, and reporting deadlines increase:
- Manual Repetition: Teams must repeatedly select, copy, paste, and clean data for every file, consuming time and reducing productivity.
- Error Growth: Small alignment mistakes spread across batches, corrupting totals, formulas, and reports while increasing rework and verification effort.
- No Standardization: Different team members paste and clean data differently, producing inconsistent worksheets, outputs, and validation results across projects.
- Poor Auditability: Manual edits leave limited traceability, making reviews, error checks, and process replication difficult during compliance reporting cycles.
G2 Rating: 4.5/5 |100% Secure
Part 6. Method 3: Converting PDF Data to Excel with PDF Software
PDF software provides dedicated conversion engines designed for structured table extraction. These tools convert PDF data to Excel with stronger layout recognition than copy-paste. Many options also export data from PDF to Excel across selected pages. As a result, cleanup time usually drops for recurring business documents.
Table-Aware PDF to Excel Conversion
PDF software detects table boundaries, headers, and cells before generating spreadsheet output. It performs better when tables include visual lines or stable spacing patterns. In addition, preview panels help users confirm selected tables before final conversion begins.
Preserving Rows and Columns
The following practices help preserve rows and columns during PDF software conversion:
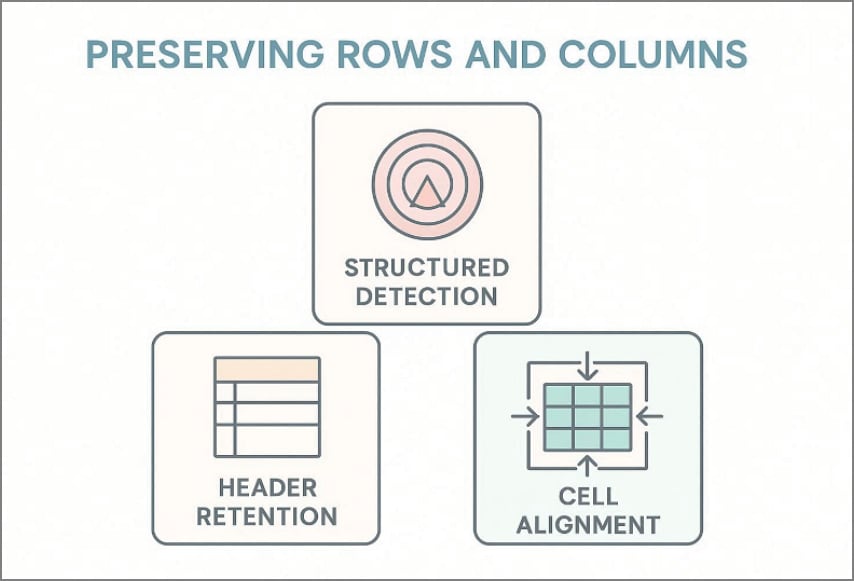
- Structured Detection: Table-aware engines map cells into grid positions, preserving row order and column relationships more reliably.
- Header Retention: Good converters keep header rows separate, reducing mislabelled fields and downstream formula confusion substantially later.
- Cell Alignment: Consistent parsing prevents amounts, dates, and item names from shifting into neighbouring columns unexpectedly afterward.
Handling Multi-Page PDFs
Now, the points below explain how PDF software handles multi-page tables more effectively:
- Page Continuity: Better tools detect repeated headers and append continued rows without restarting table structures on each page.
- Batch Export: Selected pages can be processed together, automatically creating a single worksheet from consistent multi-page reports with ease.
- Review Controls: Conversion previews reveal page breaks, missing rows, and split columns before exporting final sheets safely.
Part 7. Method 4: Extracting Data From Scanned PDFs into Excel
Scanned PDFs contain image-based text, so Excel cannot read tables directly. OCR software converts visible characters into machine-readable text before spreadsheet extraction begins. This step enables teams to extract data from a scanned PDF to Excel. However, accuracy depends heavily on image quality, layout complexity, and preprocessing choices.
When OCR Is Required
With basic in mind, the following situations indicate OCR is required before any Excel import attempt:
- Image-Only PDFs: Image-only PDFs store text as pixels, preventing selection, search, and direct table detection.
- Scanned receipts and invoices: Phone captures and scanned documents need OCR to recover rows, totals, and dates.
- Rasterized Exports: Some systems export PDFs as images, even when documents originally contained text.
Common OCR Accuracy Problems
Below are some OCR issues that reduce accuracy, even after text recognition appears successful:
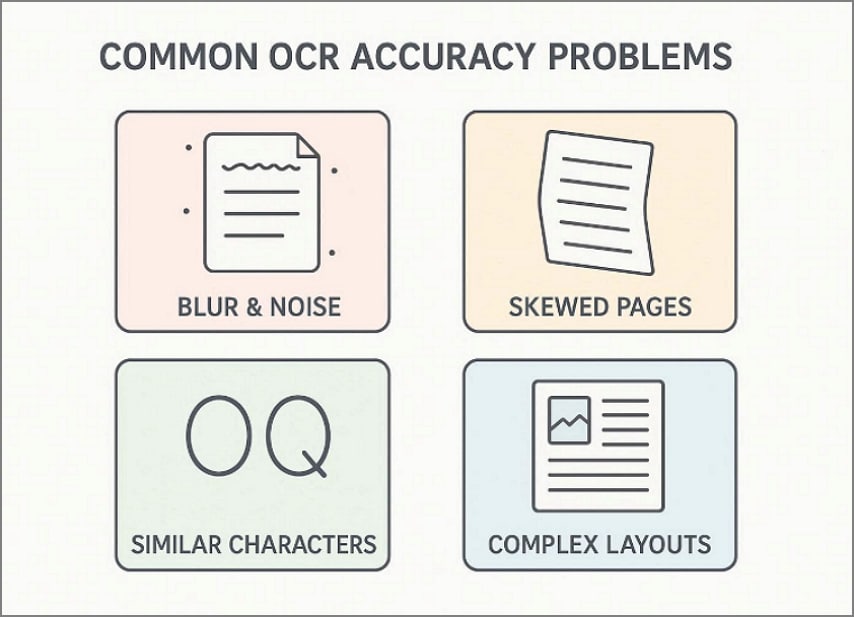
- Blur and Noise: Blur, shadows, and compression artifacts distort characters, causing substitutions and missing values.
- Skewed Pages: Tilted pages break alignment, so OCR misreads columns and merges separate cells.
- Similar Characters: OCR commonly confuses similar characters like 0, O, 1, and I.
- Complex Layouts: Multi-column forms and nested tables confuse reading order, splitting records incorrectly.
Part 8. Extracting PDF Data into Excel with PDFelement
Finance teams often receive invoices, receipts, and statements in mixed PDF formats weekly. Copy-paste breaks columns, while Excel imports fail on scanned pages. In such cases, PDFelement fits naturally into the workflow, helping teams convert PDF data to Excel with stronger table detection, guided review, and cleaner outputs for audits and reporting.
Unlike one-click converters that guess table structure blindly, PDFelement supports accuracy-first Excel workflows. Moreover, users open the file, identify whether it is digital or scanned, apply OCR only when necessary, and review extracted tables before exporting. This practical sequence reduces cleanup effort and improves confidence in downstream analysis for financial teams daily.
Guide to Extract PDF Data into Excel with PDFelement
Follow the steps below to extract PDF table data accurately and prepare cleaner Excel files for analysis:
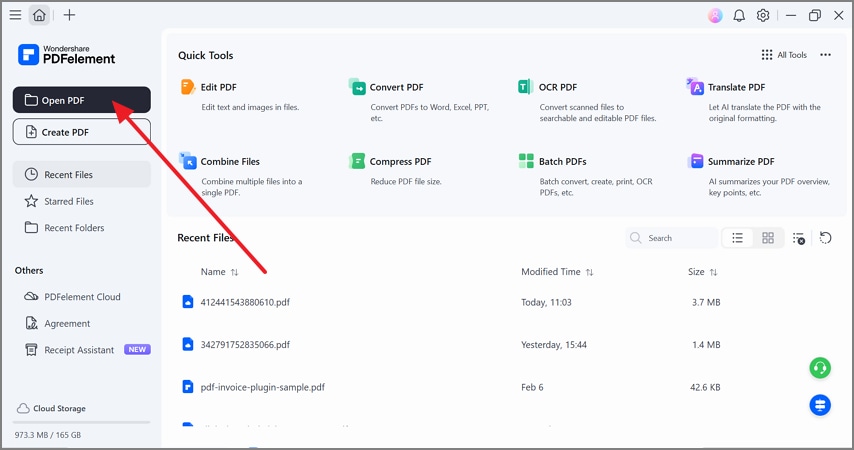
Step 1Open the PDF in PDFelement to Continue
From the PDFelement home screen, click "Open PDF" in the left panel. Next, select the source file that contains the tables you want in Excel.
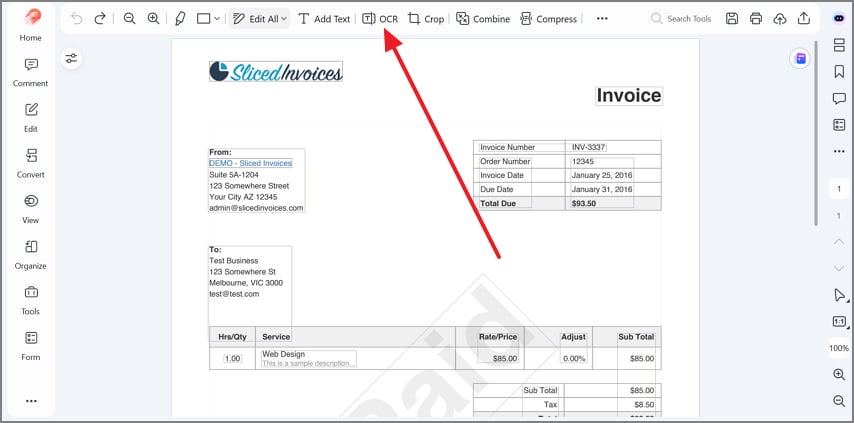
Step 2Check the PDF Type and Use OCR If Needed
Here, after opening the file, review the page and test whether the text is selectable. If the PDF is scanned or image-based, click "OCR" from the top toolbar. This step is conditional and only applies when the document needs recognition.
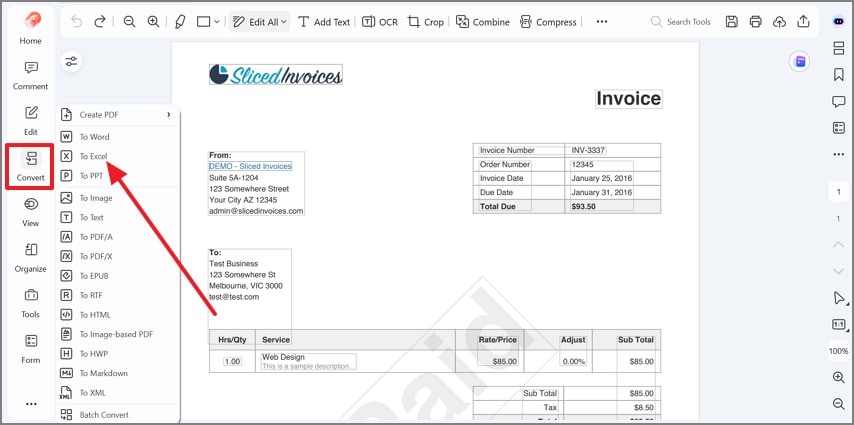
Step 3Convert the PDF Table to Excel
Now, in the left sidebar, click "Convert," then choose "To Excel" from the menu. Thus, PDFelement will prepare the table content for spreadsheet export in Excel format.
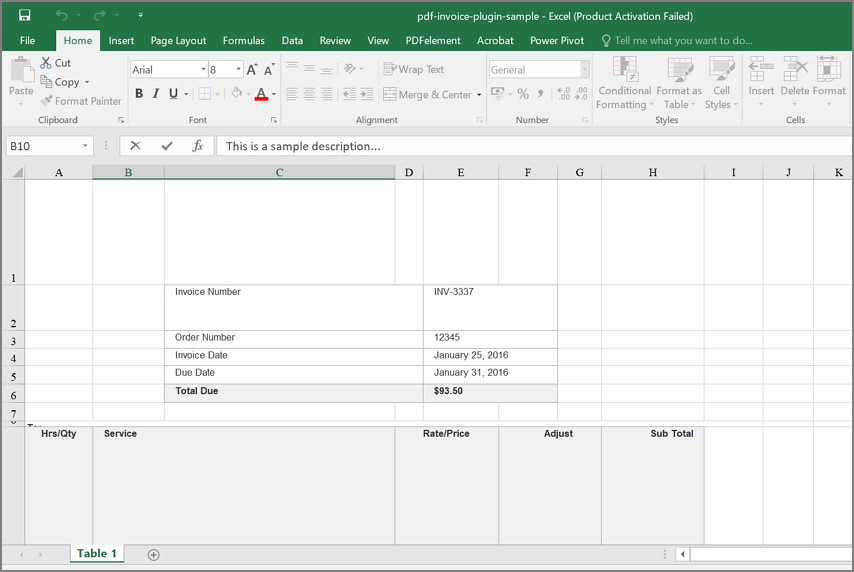
Step 4Review the Converted Excel Output Before Analysis
Finally, open the exported Excel file and review rows, columns, headers, and totals carefully. Further, check dates, amounts, and table alignment before using formulas or reports.
Part 9. Improving Excel Results After Extraction
Extracting data is only the first step. The real quality comes from the cleanup. Even when conversion works well, PDFs often bring hidden formatting issues into Excel. A short review process improves accuracy, prevents broken formulas, and makes your file ready for reporting. So, use the practical cleanup steps below to turn extracted PDF data into reliable, analysis-ready Excel tables:
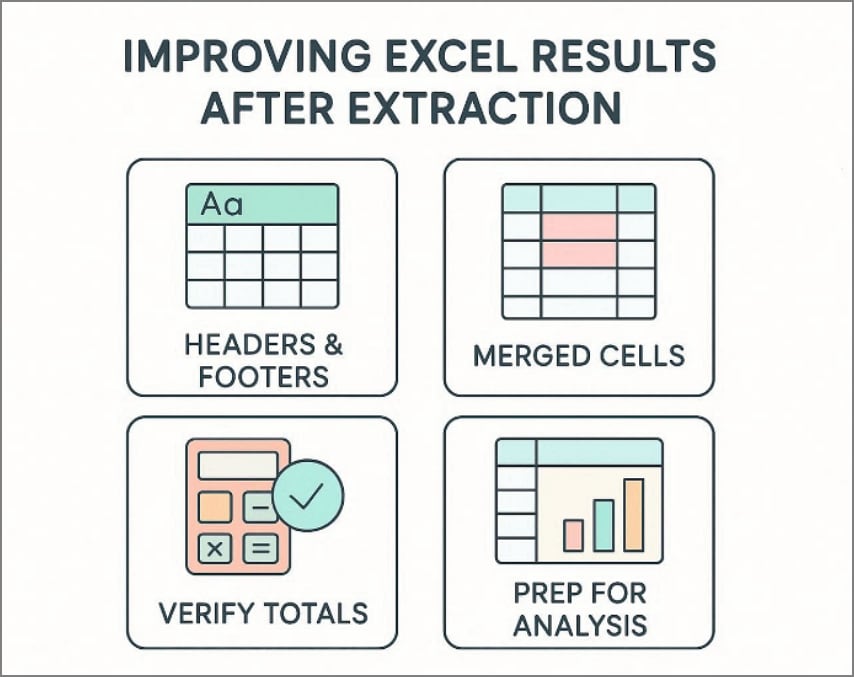
Clean Headers and Footers First
Start by removing repeated headers and footers from every imported page. These may include page numbers, company names, report titles, or timestamps. If left inside the dataset, they interrupt sorting, filtering, and formula ranges. Clean rows at the top and bottom also make the sheet easier to read.
Fix Merged Cells for Better Structure
Merged cells often appear after PDF extraction and create analysis problems. Unmerge them, then fill missing values downward where needed. This step restores row consistency and prevents errors in filters, lookups, and table formatting. A clean row-by-row structure is essential for reliable Excel work.
Verify Totals and Calculations
Always validate key numbers before using the file in reports. Recheck line-item totals, tax values, subtotals, and grand totals against the original PDF. Small alignment or OCR mistakes can change results quietly. Early verification prevents incorrect summaries and decision-making errors later.
Prepare Data for Pivot Tables or Formulas
Finally, standardize column names, date formats, and number formats. Convert text values into real numbers where necessary. Consistent columns make pivot tables, formulas, and dashboards much faster to build and maintain.
Part 10. Free and Online PDF-to-Excel Methods: What To Expect
Free and online converters can help when you need quick results. They are useful for simple files, urgent tasks, and one-time spreadsheet checks. However, expectations should stay realistic before uploading business documents or complex tables If you are learning how to convert PDF data to Excel, start with non-sensitive files. Plus, many users first search for free PDF-to-Excel tools, then compare accuracy later.
Advantages of Free Tools
The following advantages explain why free tools remain popular for lightweight tasks:
- Fast Access: Most online converters run in browsers without software installation or account setup.
- Low Cost: They provide a practical starting point for students, freelancers, and occasional users.
- Quick Testing: You can test table extraction quality before committing to paid software.
Common Drawbacks to Expect
Below are the drawbacks that matter more when your documents contain sensitive data or messy layouts:
- File Size Limits: Many services restrict page counts or uploads, blocking larger statements and reports.
- Privacy Concerns: Uploading invoices, contracts, or IDs can create compliance and confidentiality risks.
- Lower Accuracy on Tables: Free converters often misread merged cells, multi-line rows, and uneven columns.
Part 11. Common Mistakes When Extracting PDF Data into Excel
Use the extract data from PDF to Excel effectively by avoiding the common mistakes listed below:

- Same Treatment: Different PDF types behave differently, so one extraction method cannot fit every document properly. Digital files, forms, and scans require separate workflows for accurate Excel results consistently overall.
- Skip Validation: Unchecked outputs can contain shifted rows, wrong dates, and broken totals after conversion processes. Always compare extracted values against the source PDF before using reports or calculations downstream.
- Auto Trust: Excel auto-detection is convenient, but complex tables confuse column boundaries and headers. Blindly loading detected tables increases cleanup time and allows hidden structural errors later downstream.
- Ignore OCR: Poor OCR settings misread characters, especially totals, dates, and invoice numbers in scans frequently. Low-quality recognition creates spreadsheet errors that look valid until reconciliation exposes discrepancies later.
- No Preprocessing: Skewed pages, shadows, and low contrast reduce detection accuracy before extraction even starts properly. Simple cleanup, like cropping and deskewing, significantly improves OCR output and column alignment accuracy.
People Also Ask
-
How do I extract data from a PDF into Excel?
Open the PDF in a converter, select tables, then export directly to Excel. Review headers, totals, and columns afterward, because extraction errors can appear during import. -
Can Excel read data from PDFs directly?
Yes, Excel can import table data from many digital PDFs using Get Data. Scanned files usually require OCR first, because Excel cannot read image text directly. -
How do I extract data from scanned PDFs into Excel?
Use OCR software to recognize text first, then convert detected tables into Excel. Improve image quality beforehand by deskewing, cropping, and increasing contrast for better accuracy. -
What is the most accurate way to convert PDF data to Excel?
Use table-aware PDF software with OCR, then review results before saving carefully. Accuracy improves when you validate totals, fix columns, and compare source values manually. -
Why does my Excel file look misaligned?
Misalignment happens when PDF spacing, merged cells, or line breaks confuse extraction tools. Clean the sheet by unmerging cells, splitting columns, and correcting data formats manually.
Wrap-up: Extracting PDF Data Into Excel the Right Way
To conclude, reliable PDF-to-Excel extraction depends on choosing methods by file type, then validating every result. Thus, learning how to extract data from PDF into Excel is less about speed and more about preserving structure, accuracy, and consistency. For teams handling mixed digital and scanned files regularly, Wondershare PDFelement is a practical choice for reviewed, Excel-ready exports that support cleaner reporting and downstream analysis.

