
PDFelement-Powerful and Simple PDF Editor
Get started with the easiest way to manage PDFs with PDFelement!
PDF is an acronym for Portable Document Format and is rated the best format for sharing electronic documents. PDFs are everywhere and are vital in the workflows of every organization. PDF files carry all types of content, including tables. Bankers need to extract customer information from tables, teachers need to extract scores from tables to prepare transcripts, and accountants need table data to create invoices and receipts.
While there are several ways to extract tables from PDF, Python is proving to be a great method. Python is an interactive computer programming language used for website and software development. However, it also offers a platform to read and extract tables from PDF files. You can extract the desired table from PDF with Python with a suitable code snippet. This article walks you through the easiest way to extract a table from PDF with Python.
Method 1: Use Tabular-Py Python Wrapper to Extract Table From PDF
Tabular-py is a wrapper of tabular Java - a java library that allows users to read the contents of a table embedded in a PDF document. It reads the table contents and converts them to pandas DataFrame. With tabula-py, you can convert your PDF file into CSV, TSV, or JSON files. However, your system must have Java8+ and Python 3.7+. You should run the following commands to automatically download and install the required Java dependencies on your system.
$ pip install tabula-py
$ pip install tabulate
Suppose the save path for PDF with the target table is /home/Ubuntu/data.pdf; you can run the following code in the terminal to extract the table in your PDF and save it as CSV, TSV, or JSON.
Import tabula
# begin by importing the tabula library
Import tabula
# read table from pdf file
dfs = tabula-read_pdf("/home/ubuntu/data.pdf",pages="all")
# convert your PDF table into CSV format
tabula.convert_into ("/home/ubuntu/data.pdf","output.csv","outpour_format="csv", pages="all")
You can also extract and print the table from the terminal using the following code.
from tabula import read_pdf
from tabulate import tabulate
# This command reads the table in your PDF file
df = read_pdf("/home/ubuntu/data.pdf",pages="all")
# This command prints you're your PDF file in terminal
print(tabulate(df)
The read_pdf () command reads the contents of the table in your PDF file.
The tabulate () command arranges the read data in a table format.
Tips and Notes
· Make sure Java is present in your system.
· Try to have basic knowledge of Python to make your work easier.
Method 2: Use Camelot-Py Python Library to Extract Table From PDF
Camelot is another useful Python library that you can use to extract tables from PDF. The beauty of Camelot is the level of control it offers. This library gives you more power to customize your table extraction and meet your need. Furthermore, each table is a Pandas DatFrame that is easy to integrate into ETL and data analysis workflows. With the Camelot library, you can export your tables to a variety of file formats, including JSON, Excel, HTML, and Sqlite.
To install Camelot library on your system, run the following command.
$ pip install camelot-py
Unlike tabula-py, Camelot uses arrays and indices to access a particular table in your PDF file. The table is first read using the read_pdf () function and the tables stored in an array of tables. The arrays will obviously start from tables [0] then tables [1] and so forth. To print a PDF in terminal, you can run the following code.
import camelot
# extract all the tables in the PDF file
abc = camelot.read_pdf("/home/ubuntu/data.pdf")
# print the first table as Pandas DataFrame
print(abc[0].df)
The import Camelot command imports the Camelot library for use in the program. If Camelot library is not installed, Python will print an error message instead.
Camelot.read_pdf () command reads the contents of your PDF table and stores them in an array of tables abc.
The print (abc[0].df) command prints the first table in the array i.e table [0] on the terminal.
Tips and Notes
· Use the parsing function to discard bad tables based on accuracy and whitespace.
· If you want to extract tables from different pages and want to change the order of extraction, you can use the order command within the parsing function.
· Try to familiarize yourself with Python syntax to minimize conversion difficulties.
[Bonus] PDFelement: Extract Tables From PDF More Conveniently Than With Python
While Python is useful in extracting tables from PDFs, it doesn't offer the convenience of a dedicated PDF data extraction tool. Python is a programming language, and it is not easy to understand and memorize the syntax. If you are new to Python, perhaps you will read the first line and get discouraged. You require professional knowledge to easily and accurately navigate and extract tables from PDF. Even if you are a professional, the process of writing and running codes to extract table data is time-consuming and tiresome.
Fortunately, PDFelement solves this problem by giving you a convenient platform to extract tables from PDF. The interface is elegant and easy to use. If you are a newbie, you will find navigating and extracting tables from PDF extremely easy. You don't need coding knowledge or experience to extract tables on PDF with this software. Furthermore, Wondershare PDFelement is compatible with several devices and operating systems, including Windows, Mac, and iOS. You don't have to worry about adding libraries because this program is fully-packed. Again, its amazing processing speed and affordability make it a convenient tool for all users, including amateurs.
Method 1: Extract Tables While Keeping the Original Format
Sometimes you want to extract tables from PDF without changing the original format. This is useful where you need both the table and contents, you want to present the table in exactly the same format, or when you are not interested in tweaking the table layout. This process is fast and straightforward in PDFelement, as illustrated below.
Step 1 First, launch PDFelement on your device and upload the file from which you want to extract tables. Alternatively, you can right-click the PDF file and open it with Wondershare PDFelement.
Step 2 When the PDF file is loaded, go to the toolbar and click the "Convert" tab. from the options displayed below it, choose the "To Excel" option.
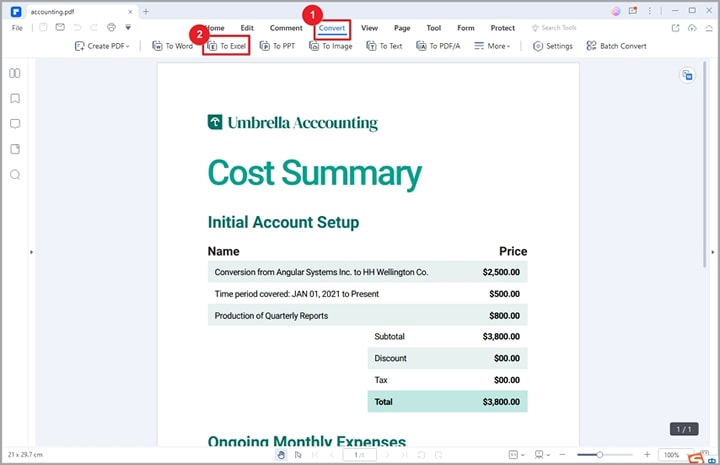
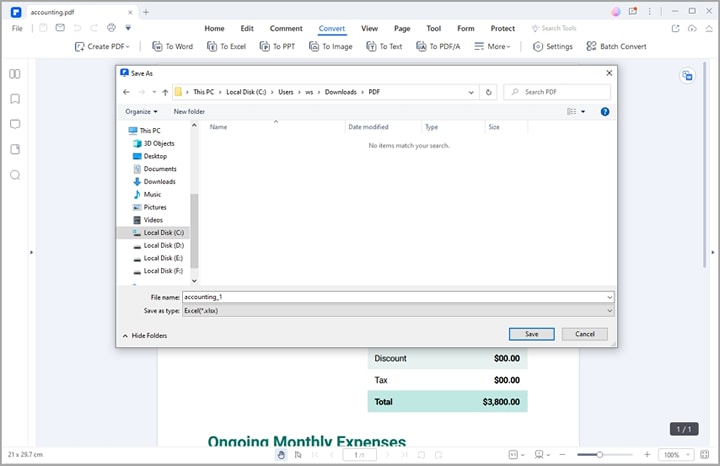
Step 3 PDFelement will automatically take you to the output "Save As" Window. Here, choose a suitable destination folder and click the "Save" button. PDFelement will immediately convert your PDF file to Excel file. Open the Excel file to check the table.
Tips and Notes
· If you are handling several files, use the batch process to save time and energy.
· If you have a multipage file and you only need a section of it, just crop it before converting PDF to Excel.
Method 2: Extract Data Only From PDF to CSV
In other cases, you are not concerned with the table format but rather the content of the table. In this scenario, you will be obliged to extract the PDF table content only. Fortunately, PDFelement allows users to extract data only from PDF to CSV. CSV is a plain text format that organizes data in a tabular form using commas.


 G2 Rating: 4.5/5 |
G2 Rating: 4.5/5 | 100% Secure
100% Secure
Wondershare PDFelement - PDF Editor Wondershare PDFelement Wondershare PDFelement allows you to extract data from a PDF fillable form. However, the PDF form must contain fillable form fields before extracting PDF table data to CSV. If the form fields are not fillable/recognizable, you need the PDFelement OCR feature to make them recognizable/fillable. The steps are illustrated below.
Step 1 Open your PDF file with PDFelement. Make sure your PDFelement version has the OCR plugin installed.
Step 2 Head to the "Form" section and click the "Recognize" icon from the several options displayed below it. PDFelement will automatically make your PDF form fields recognizable.
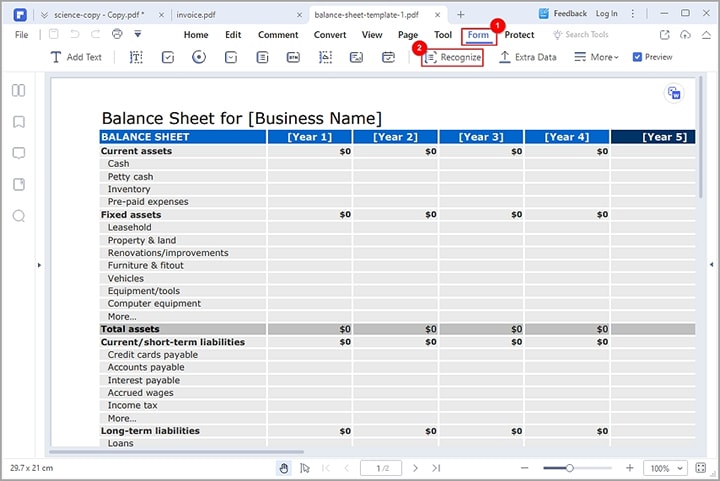
Now that the PDF file is recognizable, you need to proceed to extract table data from your PDF file as follows.
Step 1 Go to the toolbar and click the "Form" tab. From the options displayed, click the "Extract Data" option.
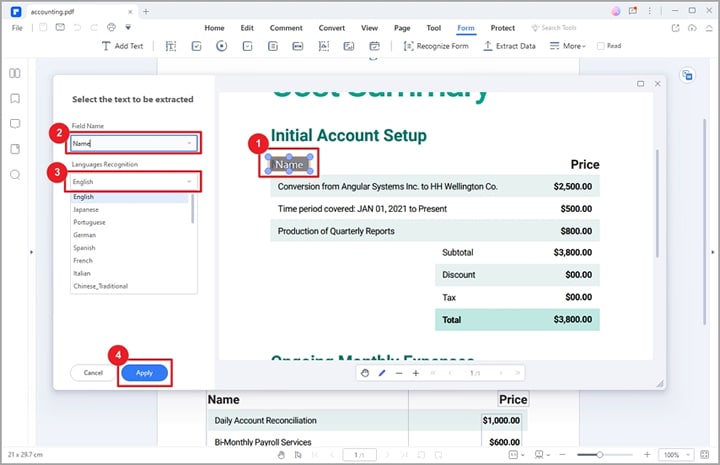
Step 2 PDFelement will display the "Extract Data" dialog window on the screen. Here, you can choose either "Extract data from form fields" or "Extract data based on selection." When you choose the "Extract data from form fields" option, your form fields will be extracted into a CSV file.
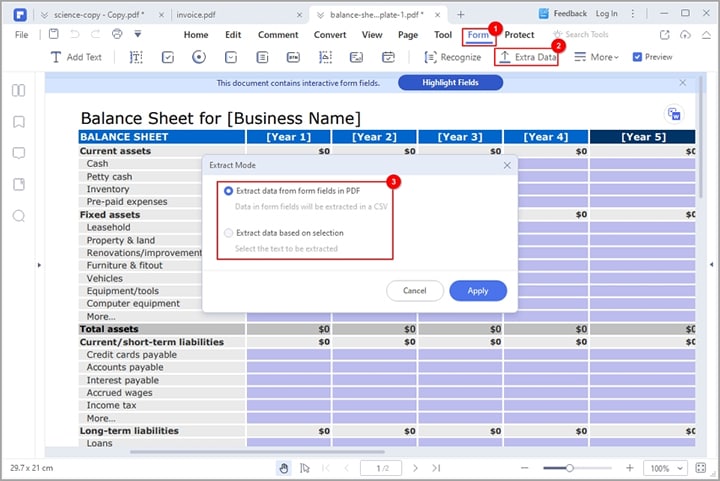
If you choose the "Extract data based on selection," you need to select each form field to be extracted using the cursor in the pop-up dialog. After that, enter the name of the selected form fields and select a suitable recognition language.
Step 3 After selecting all desired form fields, click the "Apply" button. PDFelement will immediately extract data only from PDF to CSV.
Tips and Notes
· If you want to extract data from non-fillable fields, ensure the OCR plugin is installed for PDF recognition first.
· Use batch process if you have multiple PDFs that you need to extract data from the same area or want to extract data from a PDF form with multiple tables carrying different data.
· "Extract data based on selection" feature can be applied to both text-based and scanned PDF forms.
· Since you need to select each form field manually, use the "Extract data based on selection" when you need only a little amount of data.
Extracting tables from PDF with Python requires programming knowledge and expertise. However, PDFelement brings PDF table extraction closer to you with an intuitive and user-friendly interface. The process is simple and convenient for every user, including newbies. Download PDFelement today and enjoy an unmatchable experience when extracting tables from PDF.

