Convert PDF to HTML using Python
How can I convert PDF to HTML with Python? If you want to know the proper way to convert PDF to HTML using Python, this is the best solution for you.
 100% Secure |
100% Secure | Home
>
PDF Convert
> Convert PDF to HTML using Python
Home
>
PDF Convert
> Convert PDF to HTML using Python
Converting PDF to HTML is useful in many scenarios. For example, if you want to see a web preview of a PDF document, an ideal format would be plain HTML. The reason for this is that PDF is not a responsive or interactive format on the web; HTML is a better option because it has the ability to adjust itself to your device's screen size and resolution requirements, among other things. If you need to convert PDF to HTML, Python is a good option because it has a number of packages to handle PDF documents.
How to Convert PDF to HTML using Python
If you're working on a Linux machine, the Python PDF to HTML method works well because you very likely have the tools installed already. For example, if you're using AbiWord, you can either use the command-line method or invoke the GUI. In the former scenario, you can use standard libraries to invoke the program from Python, as shown in the image below:
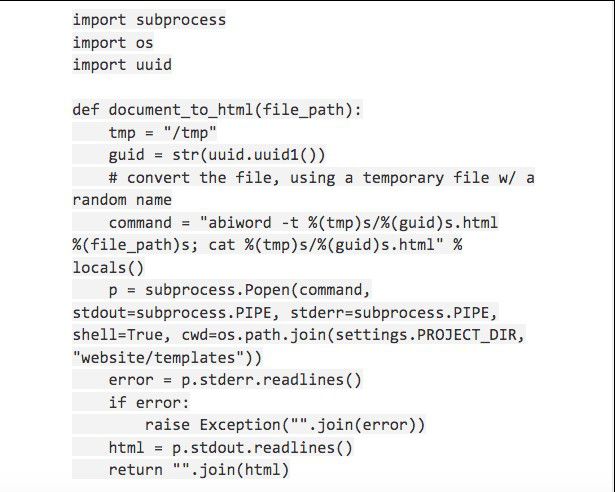
The actual conversion command - "abiword -t %(tmp)s/%(guid)s.html %(file_path)s; cat %(tmp)s/%(guid)s.html" - can be seen in the image above.
Advantages and Disadvantages of Converting PDF to HTML with Python
There are, of course, pros and cons to using Python to convert PDF to HTML. If you're familiar with Python programming, it should be a breeze to convert PDF to HTML with libraries you've probably worked with already. On the other hand, if you're relatively new, you might have a hard time figuring out which program best suits your specific situation. There are several popular forums where you can easily acquire this knowledge but it's a cumbersome process. Here are some of the other pluses and minuses.
The advantages are as follows:
- No need of a PDF converter or PDF editor
- Easily availably libraries to manage PDF documents
- Advanced features like OCR are available
At the same time, there are also several disadvantages, such as:
- Issues with encoding
- Subsequent data loss
- Improper conversion due to layout complexity of the source PDF
How to Convert PDF to HTML without Python
If you want to do away with using Python for PDF to HTML conversion altogether, there's a tool called Wondershare PDFelement - PDF Editor Wondershare PDFelement Wondershare PDFelement that can help. Not only is it great for PDF to HTML but also to convert HTML to PDF (create PDF from HTML.) Aside from an extensive range of conversion and customization options, it also offers the following features:


 G2 Rating: 4.5/5 |
G2 Rating: 4.5/5 | 100% Secure
100% Secure
- A full suite of tools to edit PDFs.
- Review, comment and annotate PDFs with extensive markup options.
- Fill, create, or convert forms into interactive PDFs using advanced tools.
- Perform batch processes for several PDF actions including conversion and OCR.
- Advanced security features to maintain confidentiality when distributing PDFs.
- Password encryption, watermarking, and other PDF protection tools.
- File size optimization - single and batch.
Believe it or not, converting PDF to HTML is a simple matter of three steps: import the source PDF, choose the output format as HTML and hit Convert. Learning these three steps is like mastering PDF file conversion because all the heavy lifting is done by the software. If you're a new user you'll love the intuitive interface and how crystal clear all the menus and functions appear. In addition, you get greater conversion speed and bulk conversion capabilities. To convert PDF to HTML, reproduce the steps shown below on your own computer.
Step 1. Open PDF
Download the EXE or DMG file of PDFelement from the official website. and install it like any other Windows or Mac app, as the case may be. You can either launch the program and use the "Open File…" button or drag your PDF file to the program icon to open it.
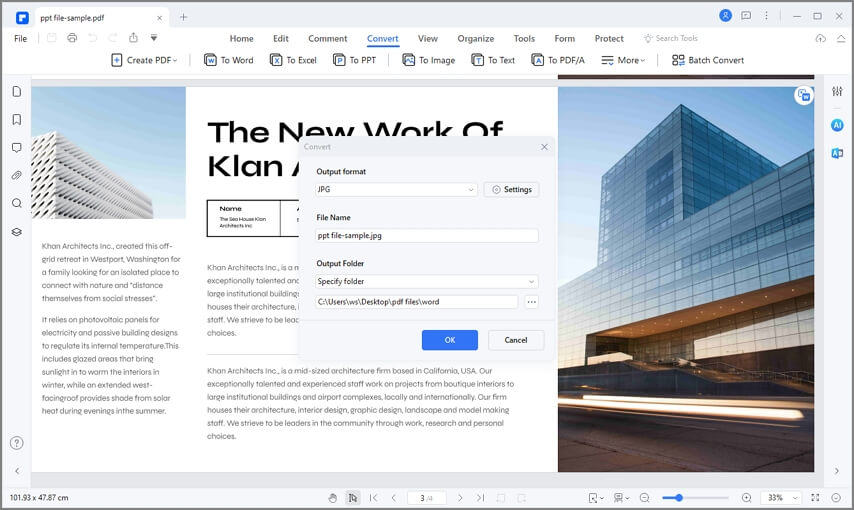
Step 2. Click the "To HTML" Button
Once the file is open, go to the "Convert" tab and click on the "To HTML" option as your output file format. Don't worry if you select a different option by mistake, because you can change it in the next window.

Step 3. Finish Converting PDF to HTML without Python
In the "Save As" dialog box that pops up, you have the option to change the output format again. You also have the "Settings" option that will give you some advanced conversion parameters as well. Click "Save" and wait for the conversion to finish.
Note: During conversion, you'll be able to see a small progress window like the one in the screenshot below. When you see it hit 100%, click "Finish" and you're all done.
G2 Rating: 4.5/5 |100% Secure
One of the biggest advantages of using a tool like PDFelement or even Adobe Acrobat DC is that there’s very little user input required for the process. We already saw how complicated it can get with Python unless you’ve done it before, and most other command-line tools are equally unpredictable or outright dangerous for your system if you don’t know exactly what you’re doing. Simply put, if the quality and accuracy of conversion are important to you, it’s better to rely on a product that offers solid customer support.
Free Download or Buy PDFelement right now!
Free Download or Buy PDFelement right now!
Try for Free right now!
Try for Free right now!


Elise Williams
chief Editor