How to Extract Images from PDF with Python
Can you extract images from PDF with Python? This post will provide the best way to help you extract image from PDF in Python.
 100% Secure |
100% Secure | Home
>
Extract Images from PDF
> How to Extract Images from PDF with Python
Home
>
Extract Images from PDF
> How to Extract Images from PDF with Python
How can we extract images from PDF with Python?
Some PDF files have images that we would like to extract and use them as resource materials or include them in other works or projects that you are doing. In such a scenario, you will have to look for a way to extract the images and save them to a preferred format. Continue reading this article to learn how Python can extract images from PDF files effectively.
How to Extract Images from PDF with Python
Python programming language comes in handy when you want to extract images from PDF files. The images can be of any different formats depending on the output that you write on the code. Also, with Python, various libraries can enable you to extract images from PDF files. Here are steps on how to extract images from PDF with Python.
- Step 1. In this case, you will need PyPDF2 and Pillow libraries installed on your computer.
- Step 2. Next, open a distribution programming language that you use, such as Anaconda, and open the Jupiter Lab.
- Step 3. After that write the following code as posted on Stack Overflow.

Alternatively, you can use PyMuPDF module which will extract images from PDF using Python in PNG format. Here is code for that:

How to Extract Images from PDF without Python
Working with Python to extract images from PDF requires one to have skills in the Python programming language, to understand the lines of code or scripts provided. Otherwise, the method above will not be of no use to you. However, if you want to get images from PDF files without Python, you need to use a PDF image extractor like Wondershare PDFelement - PDF Editor Wondershare PDFelement Wondershare PDFelement. It is a PDF software that is compatible with Windows and Mac operating systems. This software allows you to open PDF files, view PDFs, and extract images from PDF files. More so, you can extract images from PDF files and save them in different image formats like PNG, JPEG, GIF, BMP, and TIFF.


 G2 Rating: 4.5/5 |
G2 Rating: 4.5/5 | 100% Secure
100% Secure
- Its user interface is well-designed as you can easily navigate, scroll, and locate menus and icons.
- Creates PDFs files from screenshots, images, existing PDF files, and other file formats.
- The inbuilt editor allows you to modify PDF texts, images, objects, and links. You can also add watermarks, change the background, add bates and numbering, as well as headers and footers.
- It is integrated with OCR technology that scans single and multiple image-based files and makes them editable.
- It converts PDF files to formats like HTML, PowerPoint, Excel, Plain Texts, EPUB, Word, and Images.
- Annotates PDFs using text boxes, comments, stamps, and drawings.
- Enables you to create PDF forms, fill PDF forms, and extract data from PDF forms.
- Protects PDF files with passwords, permissions, and digital signatures. You can also edit the signatures or delete them permanently.
Here is a step-by-step guide on how to extract images from PDF using PDFelement.
Step 1. Enter the "Edit" Mode
Start by opening the application on your computer and click on "Open File" to upload your PDF file. Once you open the PDF file with the program, activate the edit mode by clicking on the "Edit" menu, and then switch to "Edit" mode.
Step 2. Extract Images from PDF without Python
Next, go to the image that you want to extract without python code and right-click on it. You will see lists of options that will appear on the drop-down menu. From the menu, click on the "Extract Image" option.
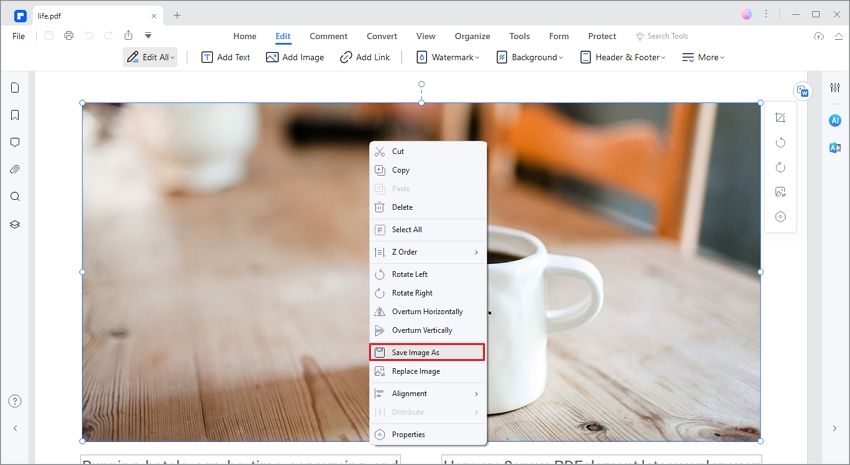
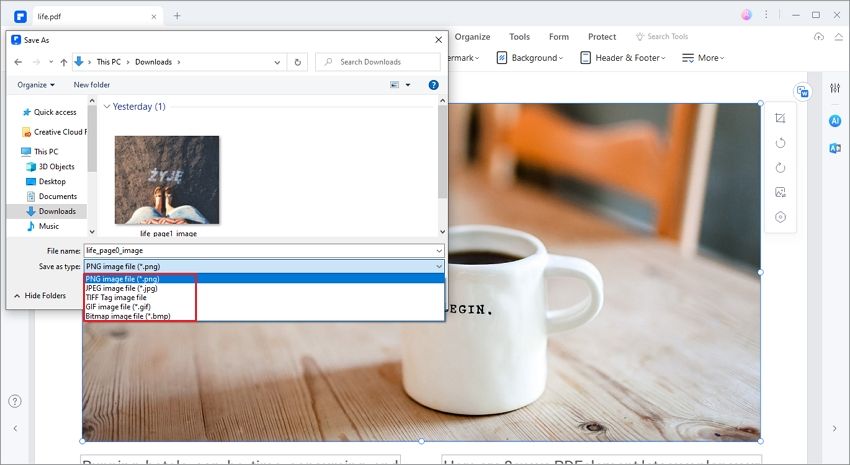
Step 3. Save the Extracted Image
After that, a save as window will pop up. Click on the "Save as Type" to choose the output format of the image such as .png, .jpeg, .bmp, .gif or .tiff. On the "File name" option, you can name your image and then click on "Save." By doing so, you will have extracted images from PDF without Python.
Free Download or Buy PDFelement right now!
Free Download or Buy PDFelement right now!
Try for Free right now!
Try for Free right now!


Audrey Goodwin
chief Editor