
Extracting data from PDFs is a common requirement in many industries, including finance, healthcare, and research. As organizations increasingly rely on PDFs for information sharing, the need to extract data from PDFs using Python has grown. However, manual data extraction can be time-consuming and error-prone, leading to inefficiencies and inaccuracies in data handling.
In this article
- Why Extract Data from PDFs Using Python?
- Key Libraries for PDF Data Extraction in Python
- PDFelement: Simplify the Entire PDF Data Extraction Process
- Benefits of PDFelement Compared to Manual Python Scripting
- How PDFelement Works Seamlessly with Python
- Step-by-Step Guide to Extract Data from PDFs Using Both Python and PDFelement
- Benefits of Combining PDFelement with Python
Python has gained immense popularity as a powerful tool for PDF data extraction. With its extensive libraries and user-friendly syntax, Python simplifies the process of extracting data from PDF Python files. This article will demonstrate how Python, combined with tools like PDFelement, makes PDF data extraction in Python easier and more efficient.
Why Extract Data from PDFs Using Python?
Python's capabilities in handling PDFs are extensive, thanks to its rich ecosystem of libraries specifically designed for Python PDF data extraction. These libraries provide various functionalities that cater to different extraction needs. Some notable libraries include:
PyPDF2
This library allows for basic text extraction and manipulation of PDF files, making it an excellent starting point for users who want to extract data from PDF using Python without complex formatting.
PyMuPDF (Fitz)
This program effectively extracts text and annotations. It provides more advanced features than PyPDF2 and excels at extracting structured information, making it ideal for documents that contain images or annotations alongside the text.
PDFMiner
This library offers advanced features for extracting text while preserving the layout structure, making it perfect for complex documents. Users can obtain detailed information about the text's position and formatting, which is crucial when working with intricate layouts.
Key Libraries for PDF Data Extraction in Python
PyPDF2
PyPDF2 is a widely used library that provides essential functionalities for reading and manipulating PDF files. It is particularly useful for users who want to extract data from PDF using Python.
What It Can Do:
- Extract Text: This function retrieves text from individual pages of a PDF document, allowing easy access to the content.
- Merge or Split PDFs: Combine multiple PDF documents into a single file or split a large PDF into smaller, manageable sections.
Examples of When to Use:
- When you need to extract text from straightforward PDFs without complex layouts, such as reports or invoices.
- Merging multiple PDFs into a single document is helpful for organizing related files.
PyMuPDF (Fitz)
PyMuPDF, also known as Fitz, is a powerful library for extracting text and annotations from PDF documents. Its advanced capabilities make it a preferred choice for users who need to perform more complex Python PDF data extraction tasks.
Capability:
- Efficient Text Extraction: Extracts text while preserving the layout, ensuring that the output maintains the original formatting.
- Access to Images and Media: This feature allows users to extract images and other media embedded within the PDF, making it ideal for visually rich documents.
Ideal Use Cases:
- When you need detailed information extracted alongside images or annotations, such as in academic papers or marketing materials.
- For extracting content from visually rich PDFs where layout preservation is crucial.
PDFMiner
PDFMiner is an advanced library specifically designed for extracting detailed information from PDFs, including text layout and structure. It is particularly beneficial for users who require precise control over how data is extracted from their documents.
Features:
- Layout Preservation: Capable of extracting text along with its layout information, making it ideal for complex documents where structure matters.
- Advanced Text Analysis: Provides tools for analyzing the layout of documents, which can be crucial when formatting is important.
When to Use:
- When you require precise control over how text is extracted based on its position in the document, such as legal contracts or technical manuals.
- For analyzing the layout of documents where formatting is crucial, ensuring that extracted data retains its intended structure.
Pandas for Tabular Data
Integrating pandas with other libraries can be highly beneficial for extracting structured tabular data from PDFs. Pandas allows you to manage and analyze the extracted data efficiently, making it an essential tool in your Python toolkit for extracting data from PDFs using Python.
Benefits:
- Data Manipulation: Easily manipulate large datasets extracted from PDFs, facilitating further analysis and reporting.
- Complex Analysis: Perform complex analyses on structured data with minimal effort, leveraging pandas’ powerful data handling capabilities.
By utilizing these libraries—PyPDF2, PyMuPDF (Fitz), PDFMiner, and pandas—users can effectively extract data from PDF using Python, tailored to their specific needs. Whether you are extracting simple text or complex tables, Python's robust ecosystem provides the tools necessary for efficient Python PDF data extraction.
PDFelement: Simplify the Entire PDF Data Extraction Process
PDFelement is a comprehensive PDF editor with a range of features designed to simplify document management. It provides user-friendly tools for creating, editing, converting, and extracting data from PDFs seamlessly.
Benefits of PDFelement Compared to Manual Python Scripting
Using PDFelement offers several advantages over traditional manual scripting methods:
- User-Friendly Interface: PDFelement is easy to use, even for those without coding experience. This accessibility makes it a great choice for individuals or teams who may not have programming skills but still need effective tools to extract data from PDFs using Python.
- OCR Technology: It includes Optical Character Recognition (OCR) capabilities that enable users to extract text from scanned PDFs effectively. This feature is particularly valuable for digitized physical documents.
- Export Options: Users can export extracted data into structured formats like Excel, CSV, or Word. Python libraries can then process these formats quickly, allowing seamless integration into existing workflows.
How PDFelement Works Seamlessly with Python
You can extract data using PDFelement's intuitive interface and then post-process it using Python scripts for further analysis. This combination enhances your workflow by leveraging the strengths of both tools—PDFelement simplifies the extraction process while Python allows advanced manipulation and analysis of the extracted data.
Step-by-Step Guide to Extract Data from PDFs Using Both Python and PDFelement
Using Python
To get started with extracting data using Python, you first need to install the necessary libraries:
bash
pip install pypdf2 pymupdf pdfminer.six pandas
Simple Code Example for Extracting Text or Table Data
Here’s a basic example demonstrating how to extract text using PyPDF2:
python
from PyPDF2 import PdfReader
# Load the PDF file
reader = PdfReader('example.pdf')
# Extract text from each page
for page in reader.pages:
print(page.extract_text())
Limitations of Python-Only Extraction
While using Python libraries for PDF data extraction provides flexibility, there are notable limitations:
- Struggles with Scanned Documents: Standard libraries may not effectively handle scanned documents without OCR capabilities. This is a significant drawback when attempting to extract data from PDF using Python, especially when the documents are primarily image-based.
- Loss of Data Structure: Unless specifically handled, extracting tables may result in a loss of formatting or structure. This can complicate further analysis if the original layout is important. Many users encounter challenges when trying to extract data from PDF Python, particularly with complex tables that require precise formatting.
Using PDFelement to Extract Data
To effectively extract data from PDF using PDFelement:
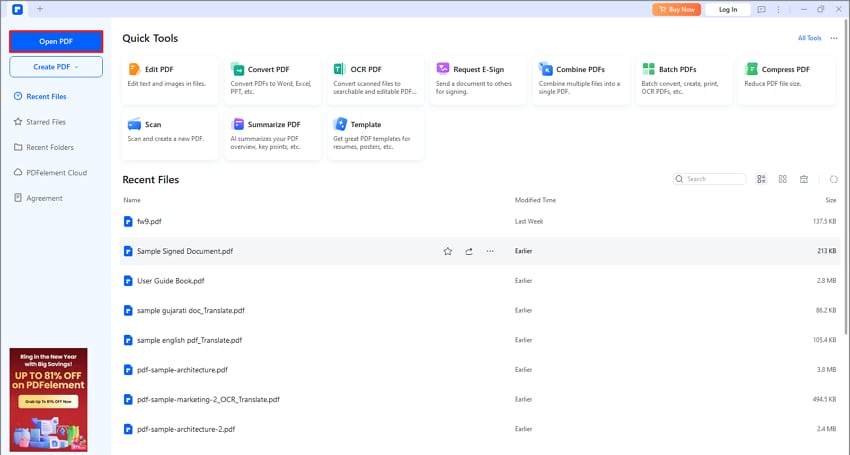
Step 1
Open PDFelement and load your PDF document.


 G2 Rating: 4.5/5 |
G2 Rating: 4.5/5 | 100% Secure
100% Secure
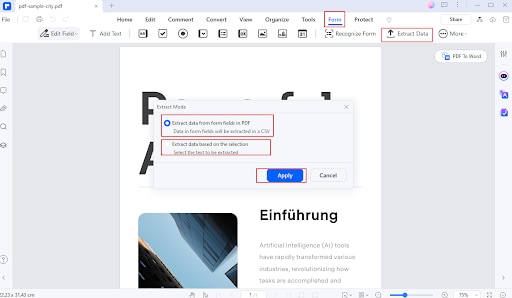
Step 2
Navigate to the Form tab and select Extract Data.
Step 3
Choose the extraction options you want (e.g., form fields or tables).
Benefits of Combining PDFelement with Python
Integrating PDFelement with Python offers several advantages for users looking to enhance their PDF data extraction in Python:
- Efficiency Boost: Combining PDFelement's intuitive interface with Python's flexibility enhances productivity by allowing users to focus on analysis rather than extraction logistics. This combination is particularly beneficial for those who regularly need to extract data from PDF using Python.
- Improved Accuracy: PDFelement utilizes OCR support for accurate extraction from scanned PDFs, which standard libraries often struggle with. This feature is crucial for ensuring that important data is not lost during the extraction process.
- Time-Saving: Automate repetitive tasks by effectively leveraging both tools. For example, use PDFelement to handle initial extractions and then apply Python scripts for deeper analysis or reporting. This approach allows businesses to streamline their workflows and improve overall efficiency in managing multiple PDF documents.
This combination is particularly ideal for businesses that deal with multiple PDF documents and complex datasets, where efficiency and accuracy in PDF data extraction Python are paramount.
G2 Rating: 4.5/5 |100% Secure
Conclusion
In conclusion, various options exist for extracting data from PDFs using Python, including libraries like PyPDF2, PyMuPDF, and PDFMiner. However, PDFelement stands out for its ability to streamline the extraction process with user-friendly features and powerful capabilities, making it an excellent choice for enhancing PDF document management. Additionally, DocuSign offers a straightforward method to decline to sign documents, which can also be integrated into your workflow, further improving the efficiency of PDF data handling.

