
PDF scraping is extracting data from PDF files using automated tools. With the increasing amount of data stored in PDF files, PDF scraping has become a crucial tool for businesses and researchers who must collect and analyze data quickly and accurately. PDF scraping can extract data such as text, tables, and images from PDF files, which can then be analyzed using data analytics tools.
PDF files often store important data such as financial reports, research papers, and government documents. Using PDF scraping tools, researchers and businesses can quickly extract and analyze data from these files to gain insights and make data-driven decisions. This makes PDF scraping an essential tool for data-driven industries and research fields.

In this article
Benefits of Scraping PDF
PDF scraping offers numerous benefits to businesses, researchers, and other professionals who need to extract data from PDF files. Here are some of the key benefits of using PDF scrapers:
- Productivity: PDF scrapers can extract large amounts of data in a fraction of the time it would take to extract the same data manually. This increased productivity allows businesses and researchers to focus on analyzing the data rather than spending hours extracting it.
- Accuracy: PDF scrapers use advanced algorithms to extract data accurately, reducing the risk of errors that can occur during manual data extraction. This ensures that the extracted data is reliable and essential for data-driven decisions.
- Cost-effectiveness: By automating the data extraction process, PDF scrapers can significantly reduce the time and cost associated with manual data extraction. This allows businesses and researchers to save money on resources and personnel needed for manual data extraction.
- Flexibility: PDF scrapers can extract various types of data, including text, tables, and images, allowing users to extract the specific data they need for their analysis. This flexibility allows users to customize their data extraction according to their needs.
- Ease of use: PDF scrapers are user-friendly and require minimal technical knowledge, making them accessible to many users. This ease of use reduces the learning curve associated with manual data extraction, making the process more efficient overall.
- Compatibility: PDF scrapers can extract data from different formats and versions, making them compatible with many PDF files. This compatibility ensures that users can extract data from any PDF file they need, regardless of its format or version.
PDFelement as a PDF Scraper
PDFelement is a powerful PDF editor and converter that can extract data from PDF files, making it a useful tool for PDF scraping. With its advanced features and user-friendly interface, PDFelement is an excellent option for businesses and researchers who need to extract data from PDF files quickly and accurately.


 G2 Rating: 4.5/5 |
G2 Rating: 4.5/5 | 100% Secure
100% Secure
Some of the key features of PDFelement as a PDF scraper include:
- Data extraction: PDFelement allows users to extract data from PDF files using its advanced OCR (Optical Character Recognition) technology. Users can extract data from PDF files in various formats, including text, tables, and images.
- Customization: PDFelement offers a high level of customization for data extraction, allowing users to choose the specific data they need to extract. This feature is particularly useful for researchers and businesses that need to extract specific data points for their analysis.
- Automation: PDFelement can automate the data extraction process, saving users time and reducing the risk of errors that can occur during manual data extraction.
- Compatibility: PDFelement can extract data from PDF files of different formats and versions, making it a versatile tool for data extraction.
- User-friendly interface: PDFelement is easy to use, even for users with limited technical knowledge. Its intuitive interface and straightforward design make it accessible to many users.
How to Use PDFelement as a PDF Scraper
Using PDFelement as a PDF scraper is a straightforward process. Here is a step-by-step guide on how to use PDFelement as a PDF scraper:
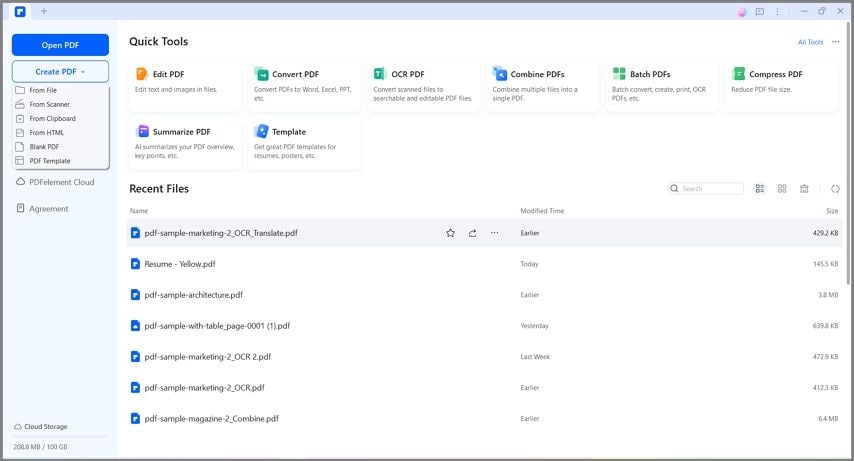
Step1
Launch PDFelement and upload your PDF form by dragging and dropping it or using the "Open PDF" button.
G2 Rating: 4.5/5 |100% Secure
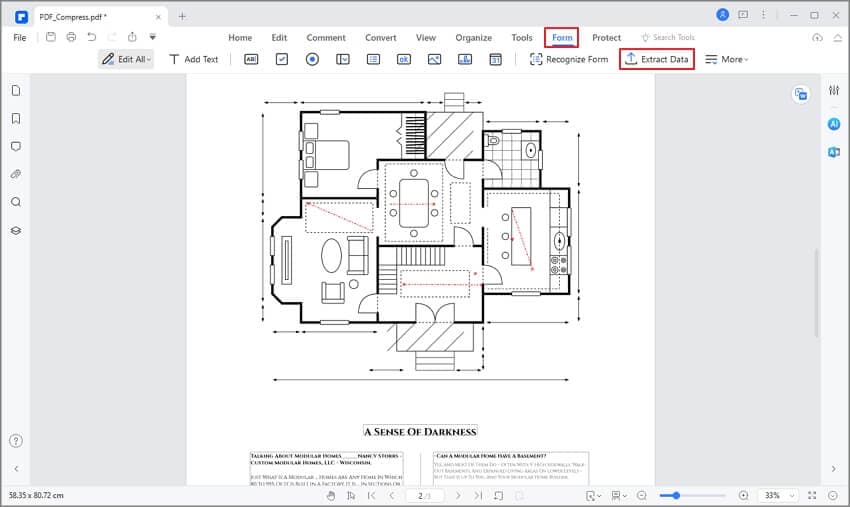
Step2
Click on "Form" > "Extract Data" to open a new dialogue window.
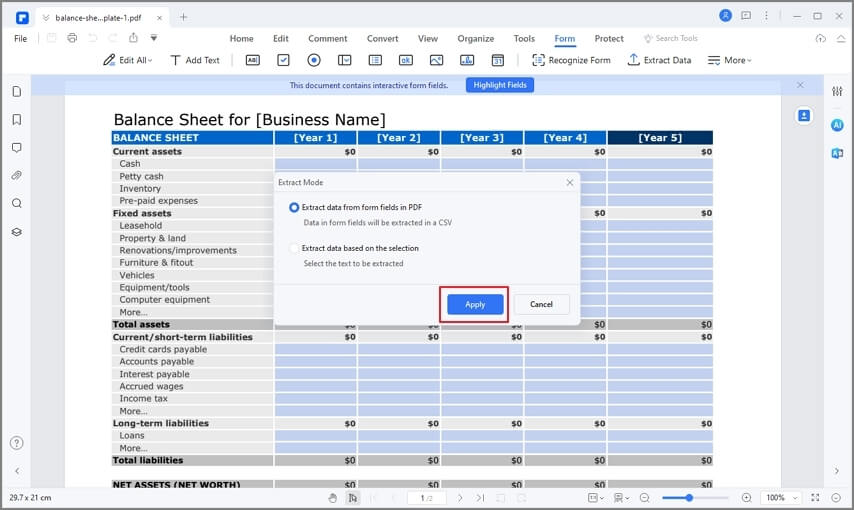
Step3
Select "Extract data from form fields in PDF" and click "Apply."
G2 Rating: 4.5/5 |100% Secure
Step4
The program will extract the data into a CSV file. Click "Open" to access the data when the process is complete.
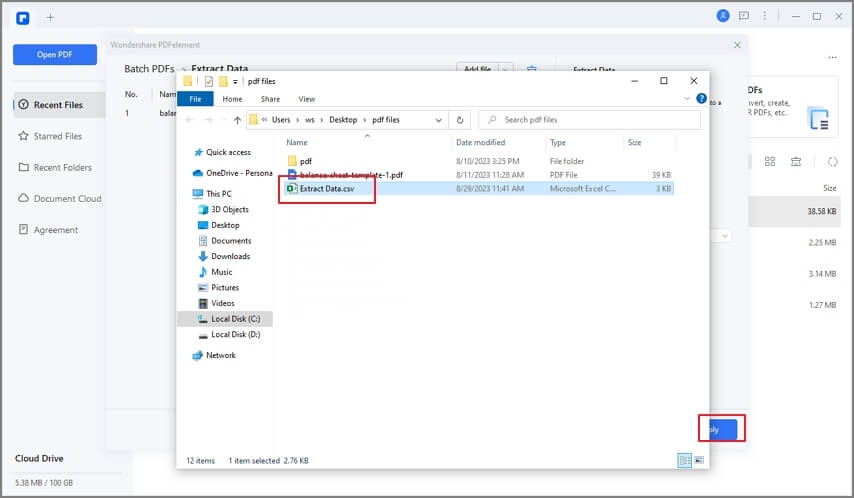
Here are some tips and tricks for efficient PDF scraping using PDFelement:
- Use the OCR feature to extract data from scanned PDF files that do not contain searchable text.
- Use the batch processing feature to extract data from multiple PDF files
- Use the data extraction templates feature to save time when extracting data from similar PDF files.
- Use the preview feature to check the extracted data for accuracy before exporting it to another file format.
Overall, PDFelement is a powerful and easy-to-use tool for PDF scraping. Following these steps and tips, you can efficiently extract data from PDF files and save time on manual data extraction.
Advantages of Using PDFelement as a PDF Scraper
Several tools are available for PDF scraping, including Adobe Acrobat, Tabula, PDFTables, and PDFelement. While each tool has strengths and weaknesses, PDFelement stands out in many ways.
Compared to other PDF scraping tools, PDFelement offers a more user-friendly and intuitive interface. Its data extraction process is simple and efficient, allowing users to easily extract data from PDF files. PDFelement's OCR feature also makes extracting text from scanned PDFs possible, which many other PDF scraping tools cannot do.
PDFelement's data extraction templates feature also a significant advantage. With this feature, users can save time by creating templates for similar PDF files, which can then be used to extract data with just a few clicks. This feature is especially useful for users who need to extract data from multiple PDF files with a similar structure.
Another advantage of PDFelement as a PDF scraper is its batch processing feature. Users can extract data from multiple PDF files simultaneously, saving time and increasing productivity. This feature is particularly useful for businesses or organizations that deal with large amounts of data.
PDFelement also offers several export options, including Excel, CSV, and plain text formats, making it easy for users to analyze the extracted data in other programs or software. PDFelement provides powerful data cleaning and manipulation tools, such as text formatting and table merging, allowing users to prepare the extracted data for further analysis.
G2 Rating: 4.5/5 |100% Secure
Scenarios of PDFelement Scraper
PDFelement's data scraping capabilities are useful in a wide range of scenarios. This section will explore some of the most common use cases where PDFelement's scraper can be particularly beneficial.
Research
Research is a field that heavily relies on data analysis, and PDFelement's scraper can be a useful tool for extracting and analyzing data from various sources.
Academic articles and reports often contain valuable data that researchers must extract and analyze. PDFelement's scraper can help researchers extract data from these documents quickly and accurately, reducing the time and effort required for manual data entry.
Surveys and questionnaires are common research tools used to collect data from study participants. PDFelement's scraper can extract and analyze survey data, saving researchers valuable time and effort. With PDFelement, researchers can easily convert survey results into a usable format, such as a spreadsheet, allowing for easier data analysis.
Government and policy research often involves analyzing large amounts of data, including reports, policy documents, and legislative texts. PDFelement's scraper can extract relevant data from these documents, allowing policymakers and researchers to quickly identify patterns and trends.
Market research involves collecting and analyzing data on consumer behavior, market trends, and competitor activity. PDFelement's scraper can extract data from market research reports, social media analytics, and other sources, allowing businesses to gain valuable insights into market trends and consumer behavior.
Medical and scientific research involves analyzing large amounts of data from various sources, including clinical trials, medical records, and research articles. PDFelement's scraper can extract relevant data from these documents, allowing researchers to identify patterns and trends useful in developing new treatments and therapies.

Business
PDFelement's scraper can also be useful for businesses extracting and analyzing data from various sources.
Invoicing and billing often involve working with large amounts of data, including customer information and purchase histories. PDFelement's scraper can extract this data from invoices and billing statements, allowing businesses to quickly identify customer buying patterns and trends.
Financial reporting involves analyzing data from various financial documents, including balance sheets, income statements, and cash flow statements. PDFelement's scraper can extract relevant data from these documents, allowing businesses to quickly generate accurate financial reports.
Market research involves collecting and analyzing data on consumer behavior, market trends, and competitor activity. PDFelement's scraper can extract data from market research reports, social media analytics, and other sources, allowing businesses to gain valuable insights into market trends and consumer behavior.
Human resources management involves collecting and analyzing data on employee performance, attendance, and other factors. PDFelement's scraper can extract relevant data from performance reviews, timesheets, and other HR documents, allowing businesses to identify trends and patterns in employee behavior and make data-driven decisions.
G2 Rating: 4.5/5 |100% Secure
Legal
PDFelement's scraper can also be a valuable tool for legal professionals looking to extract and analyze data from various legal documents.
Discovery is an important part of the legal process, requiring attorneys to gather and analyze large amounts of data from various sources. PDFelement's scraper can extract data from legal documents, including contracts, agreements, and court filings, allowing attorneys to quickly identify relevant information and build stronger cases.
Contract management is an important part of many legal practices involving reviewing and analyzing large contracts and agreements. PDFelement's scraper can extract relevant data from these documents, allowing attorneys to quickly identify key terms and provisions, monitor contract compliance, and manage risk.
Intellectual property law protects and manages valuable intellectual property assets, including patents, trademarks, and copyrights. PDFelement's scraper can extract data from IP documents, allowing attorneys to quickly identify relevant information and monitor the status of IP assets.
Legal research analyzes data from various sources, including case law, statutes, and regulations. PDFelement's scraper can extract relevant data from these sources, allowing attorneys to quickly find relevant information and build stronger legal arguments.
Conclusion
PDFelement's PDF scraping capabilities provide a powerful tool for data extraction and analysis. It offers a user-friendly interface and a wide range of features, making it an excellent choice for researchers, business analysts, and legal professionals. Its ability to extract data accurately and quickly from PDFs can save time and increase productivity. PDFelement provides a cost-effective solution for organizations that need to extract data from PDFs frequently, allowing them to improve their efficiency and streamline their workflow.

