
Table of Contents
A scanned PDF can look perfectly readable and still be impossible to edit. You click a paragraph, expecting a text cursor, but the whole page gets selected like a picture. That happens because many scanned PDFs are image-based: the scanner captured the page visually instead of saving the words as editable text.
To edit scanned PDF files properly, you usually need OCR first. OCR, short for optical character recognition, reads the image of the page and turns the visible letters into searchable, selectable, editable text. Once that conversion is done, you can correct typos, replace paragraphs, move images, copy text, or export the file to Word, Excel, or another format.
This guide explains how to edit a scanned PDF on Windows, Mac, online tools, Microsoft Word, Google Docs, and Adobe Acrobat. It also covers which method to choose when layout matters, how to improve OCR accuracy, and what to do when the converted file does not look right.



 G2 Rating: 4.5/5 |
G2 Rating: 4.5/5 | 100% Secure
100% Secure
Why Scanned PDFs Are Hard To Edit
A normal digital PDF usually contains real text. Even if the layout is locked, the document still has characters, fonts, spacing, and image objects that a PDF editor can detect. A scanned PDF is different. It is often just a photograph of a page wrapped inside a PDF container.
That is why a scanned contract, invoice, receipt, book page, or application form may not let you edit anything directly. The words are visible to your eyes, but the software sees pixels.
Scanned PDF vs. Regular PDF
A regular PDF might be created from Word, Excel, PowerPoint, InDesign, or another digital source. In that case, the PDF normally stores the text as text. You can select words, search for phrases, copy paragraphs, and edit content with a PDF editor.
A scanned PDF is created by scanning paper or saving an image as PDF. The page may contain typed text, signatures, stamps, tables, and handwritten notes, but those elements are flattened into one page image. Before editing, you need to convert scanned PDF to editable PDF using OCR.
There is a quick way to check which type you have: open the PDF and try selecting one word. If you can highlight individual words, the file already contains text. If clicking or dragging selects the whole page image, it is probably scanned.
What OCR Actually Does
OCR analyzes the image of each page, identifies characters, reconstructs words and lines, and creates a text layer. Good OCR software also tries to preserve the original layout, including columns, tables, headers, footers, and page spacing.
There are usually two common OCR output modes:
Searchable PDF
The page still looks like the original scan, but a hidden text layer is added behind or above the image. This is useful for archiving, searching, copying text, and making documents easier to index. It is not always the best choice if you need to rewrite the document heavily.
Editable PDF
The software converts recognized areas into editable text and image objects. This is the better option when you want to change text, delete content, replace images, update dates, or clean up a scanned document.
If your goal is “how to edit scanned PDF text,” choose an OCR mode that creates editable text, not only searchable text.
When OCR May Not Be Enough
OCR is powerful, but it is not magic. A clean scan of typed text usually converts well. A skewed page, tiny font, faint ink, shadows, handwritten notes, or a complex table may need manual correction after OCR.
The Library of Congress digital preservation guidance and many digitization standards also emphasize scan quality because OCR accuracy depends heavily on the source image. If the original scan is poor, even the best editor may misread characters such as “0” and “O,” “1” and “l,” or punctuation in small fonts.
Best Way To Edit a Scanned PDF on Windows or Mac
For most work documents, the safest workflow is to use a desktop PDF editor with built-in OCR. Online tools are convenient, but desktop software is usually better when the file contains private information, has many pages, or needs layout preservation.
PDFelement is a practical choice for this workflow because it combines OCR, PDF editing, conversion, page organization, annotation, forms, signing, and compression in one place. That matters because editing a scanned PDF rarely ends at text replacement. You may also need to reorder pages, redact private details, add a signature, compress the final file, or export it to Word or Excel for further editing.
Below is the typical workflow for how to edit a scanned PDF using PDFelement.
G2 Rating: 4.5/5 |100% Secure
Step 1: Open the Scanned PDF
Launch PDFelement and open your scanned PDF from the home screen. You can use the Open PDF button or drag the file into the workspace.
Before running OCR, take a quick look at the scan. If the pages are sideways or upside down, rotate them first. If the document has blank pages, remove them. OCR works better when the page image is clean and correctly oriented.
If you are working with a long file, check whether all pages need OCR. Some PDFs are mixed: a few pages may be digitally generated while others are scanned attachments. Running OCR only where needed can save time.
Step 2: Run OCR To Make the PDF Editable
When PDFelement detects that a document is scanned, it may prompt you to perform OCR. Choose the OCR option and select the document language. This setting matters. A file in English, French, German, Portuguese, Arabic, Turkish, Korean, or another language should be recognized using the correct language pack to reduce errors.
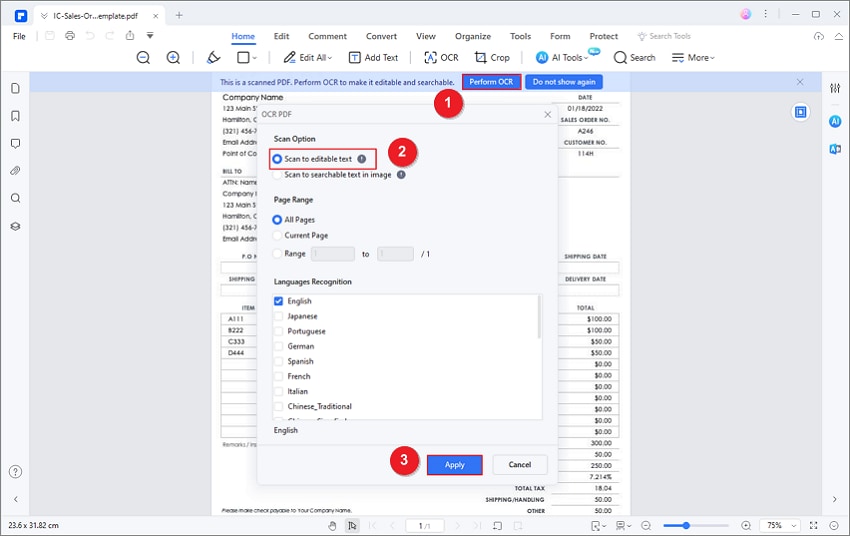
Choose the output type based on what you need:
- If you only need to search or copy text, a searchable PDF may be enough.
- If you need to change wording, replace numbers, remove paragraphs, or adjust layout, choose an editable PDF output.
For documents with tables, invoices, statements, or data-heavy reports, you may also want to export the OCR result to Excel. For letters, contracts, proposals, and forms, PDF or Word output usually makes more sense.
Step 3: Edit Text, Images, and Page Elements
After OCR finishes, open the editing tools. You should now be able to click text areas and make changes. For example, you can correct a misspelled name, update an address, remove an outdated clause, or add a new paragraph.
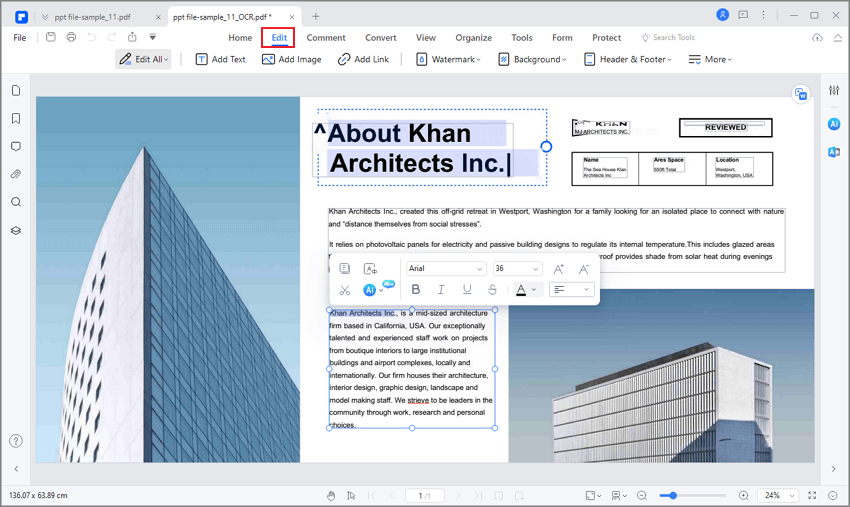
Keep the edits small if the document must retain its original appearance. OCR-generated text may not match the original font perfectly, especially if the scan came from an old printed document. Replacing a short phrase is usually cleaner than rewriting an entire page inside the original layout.
You can also edit images and page objects. If the scan includes a logo, stamp, chart, or photo, select the object and move, delete, crop, or replace it as needed. For scanned forms, you may prefer adding text boxes on top of the existing page rather than converting every line into editable text. That approach often preserves the original form structure better.
PDFelement is especially useful when you need follow-up PDF tasks after OCR. For instance, after correcting text, you can add comments for review, insert a signature field, redact sensitive numbers, combine supporting files, or compress the PDF before emailing it. Those are common real-world steps that basic OCR converters do not always handle well.
Step 4: Save, Export, or Share the Edited Scanned PDF
Once your edits are complete, save a new copy instead of overwriting the original scan. Keeping the original file is useful if you need to compare OCR results or recover a page that was converted incorrectly.
Use Save As when you want to preserve both versions. If someone else needs to keep editing the file, export it to Word. If the document is final, save it as a PDF. If the file is large because of high-resolution scanned images, compress it before sending.
For legal, financial, medical, or HR documents, also check whether your final PDF needs security controls. Password protection, redaction, and permission settings can be useful if the scanned file contains personal information.

G2 Rating: 4.5/5 |100% Secure
Other Ways To Convert a Scanned PDF to an Editable PDF
PDFelement is a strong all-around option when you want a reliable desktop workflow, but it is not the only way to edit scanned PDF files. The right method depends on the document and what “editing” means in your situation.
If you only need to extract text from a simple scan, a free option may be enough. If you need to preserve layout, edit a multi-page contract, or handle private files, use a dedicated PDF editor with OCR.
Edit a Scanned PDF Online
Online OCR tools let you upload a scanned PDF, choose a language, and convert it into editable text or another format. HiPDF, for example, offers online OCR and PDF conversion tools that can be used from a browser without installing software.

The usual workflow is simple: open the online OCR tool, upload the scanned PDF, select the document language and output format, then run the conversion. After processing, download the editable file.
This method is convenient for occasional, non-sensitive documents. It is less ideal for files containing contracts, IDs, tax records, medical documents, confidential business information, or anything you would not want to upload to a third-party server.
Online tools can also have limits on file size, page count, batch processing, or output formats. If your scanned PDF is large, you may need to compress or split it first.
Edit a Scanned PDF in Microsoft Word
Microsoft Word can open PDFs and convert them into editable Word documents. For some simple PDFs, that is enough. The process is usually: open Word, choose File > Open, select the PDF, accept the conversion prompt, and edit the resulting document.
This works best when the PDF already contains text or when the scan is extremely clean and simple. For image-only scanned PDFs, Word is not a full OCR-focused PDF editor. It may struggle with complex layouts, multi-column pages, tables, stamps, forms, and image-heavy documents.
Use Word if your main goal is to rewrite the content as a document rather than preserve the exact scanned layout. For example, converting a one-page typed notice into an editable Word file may be fine. Editing a signed contract scan while keeping the same formatting is a different task and needs a stronger OCR workflow.
Edit a Scanned PDF in Google Docs
Google Docs can perform OCR when you upload a scanned PDF or image to Google Drive and open it with Google Docs. It can recognize text in many languages and is useful when you need a free way to extract text quickly.
The workflow is straightforward: upload the scanned PDF to Google Drive, right-click the file, choose Open with > Google Docs, and wait for Google Docs to create an editable version.
The trade-off is formatting. Google Docs may separate the original page image from the recognized text, alter spacing, lose table structure, or simplify columns and lists. It is often good for text extraction, not precise PDF editing.
Google’s own Drive help explains file and formatting considerations for OCR in Google Docs, including the importance of clear text and supported file types. You can review the current details in Google Drive Help.
Use Google Docs when you need free OCR for a simple file and do not care much about the original layout. Avoid it when the final document must look like the scanned original.
Edit a Scanned PDF in Adobe Acrobat
Adobe Acrobat includes OCR through its Scan & OCR tools. A typical workflow is to open the scanned PDF, use Scan & OCR, recognize text in the file, then use Edit PDF to modify the converted content.
Acrobat is a capable option, especially in workplaces that already use Adobe subscriptions. It can recognize text, make scanned documents searchable, and support editing after OCR. The main drawbacks for some users are cost, interface complexity, and subscription requirements.
Adobe’s official documentation on scanning and OCR in Acrobat is a useful reference if you already have Acrobat and want to use its built-in tools.
How To Choose the Right Method
The best way to edit a scanned PDF depends less on the brand name and more on the type of document in front of you. A one-page receipt, a 40-page contract, and a scanned table all need different handling.
Use a Desktop PDF Editor for Layout-Sensitive Files
If you need the final PDF to look close to the original, use a PDF editor with OCR, such as PDFelement or Acrobat. This is the better choice for contracts, forms, certificates, business letters, invoices, and reports.
Desktop tools are also preferable for private documents because you do not have to upload files to an online converter. That can matter for company policies, client agreements, personal IDs, bank statements, or internal records.
Use Online OCR for Quick, Low-Risk Conversions
Online OCR is useful for small, non-confidential files. If you scanned a public handout, a simple memo, or a short printed page and only need editable text, a browser-based converter can be fast.
The main question is not just “Can it convert the file?” but “Am I comfortable uploading this file?” If the answer is no, stay with offline software.
Use Word or Google Docs for Text Extraction
Word and Google Docs are better for pulling text out of a scan than for editing the PDF itself. They are helpful when you plan to rewrite the document, copy the content into another file, or rebuild the layout from scratch.
They are weaker when you need to edit directly on the original PDF page. Formatting changes are common, especially with tables, columns, scanned signatures, and mixed text-image layouts.
Use Adobe Acrobat if Your Team Already Has It
If your company already pays for Acrobat, it may be the simplest option because it is already approved and installed. For individual users who only need OCR and PDF editing occasionally, a lighter PDF editor may be easier to justify.
Tips To Get Better OCR Results Before Editing
OCR quality starts before you open the PDF editor. A clean scan gives the software better information to work with. A poor scan forces the OCR engine to guess.
For most printed documents, scan at around 300 dpi. That is usually enough for clear typed text without creating unnecessarily huge files. Very small text, archival documents, or faint print may benefit from a higher resolution, but bigger is not always better if it slows processing or creates oversized PDFs.
Use black-and-white or grayscale for text-heavy documents unless color is needed. Color scans can preserve stamps, logos, and highlighted marks, but they may also capture background noise. If the page has shadows, low contrast, or yellowed paper, adjust brightness and contrast before OCR.
Lay the document flat on the scanner bed. Curved pages near a book spine, folded corners, and tilted pages can cause recognition mistakes. If the scan is skewed, use deskew or rotate tools before running OCR.
Check the OCR language carefully. A German invoice recognized as English, for example, may produce avoidable errors. For bilingual documents, choose the most relevant language options if the software supports them.
After OCR, proofread important sections manually. Names, addresses, dates, totals, account numbers, and legal clauses deserve extra attention. OCR mistakes often hide in places where a single character matters.
G2 Rating: 4.5/5 |100% Secure
Common Problems When Editing Scanned PDFs
Even with good OCR software, scanned PDFs can behave unpredictably. Here are the issues users run into most often and how to handle them.
The PDF Still Will Not Let Me Edit Text
The file may have been converted into a searchable PDF rather than an editable PDF. Searchable OCR adds a text layer for selecting and searching, but it may not turn the page into editable text blocks.
Run OCR again and choose an editable output mode if available. If the PDF is protected, you may also need permission to edit it.
The Formatting Looks Different After OCR
This is common with scanned files. OCR software tries to rebuild the page, but it may not know the original font, spacing, or table structure. If the document must look exact, make small edits directly in the PDF instead of exporting everything to Word.
For forms and certificates, adding text boxes over the scan can sometimes look cleaner than converting the whole page into editable objects.
The OCR Text Has Too Many Mistakes
Poor scan quality is the usual cause. Rescan the page if possible. Use a higher resolution, improve contrast, straighten the page, and choose the correct OCR language.
If you cannot rescan, try preprocessing the image: crop margins, rotate the page, remove shadows, or convert to black-and-white. Then run OCR again.
Tables Do Not Convert Correctly
Tables are harder for OCR than normal paragraphs. If you need the data, export to Excel or a spreadsheet format if your PDF tool supports it. If the visual layout matters more than the data, keep the PDF format and manually correct the table cells that changed.
For scanned financial statements, invoices, or inventory lists, always verify totals and decimal points after conversion.
The File Becomes Too Large After Editing
Scanned PDFs often contain high-resolution page images. After OCR and editing, the file may remain large. Use PDF compression after you finish editing, not before, unless the file is too large to process.
Compressing too early can reduce image quality and hurt OCR accuracy.
People Also Ask
-
Can I edit a scanned PDF?
Yes, but you usually need OCR first. A scanned PDF is often an image of a page, not editable text. OCR converts the image into recognized text so you can edit, search, copy, or export it. -
How do I edit a scanned PDF without changing the layout?
Use a desktop PDF editor with OCR and choose an editable PDF output. After OCR, make small text edits inside the PDF rather than exporting the whole file to Word. For forms or certificates, adding text boxes on top of the original scan may preserve the layout better. -
How can I convert scanned PDF to editable PDF?
Open the file in a PDF editor with OCR, run OCR on the scanned pages, select the correct language, and choose an editable PDF output. Tools such as PDFelement and Adobe Acrobat can do this on desktop. Online OCR tools can also convert scanned PDFs, but they may be less suitable for private or large files. -
Can I edit a scanned PDF for free?
Yes, in some cases. Google Docs can extract text from scanned PDFs, and some online OCR tools offer free conversions with limits. Free methods are best for simple files where formatting is not critical. For accurate layout preservation and private documents, a dedicated PDF editor is usually more reliable. -
Why can’t I select text in my scanned PDF?
The text is probably part of a page image. The PDF displays the words visually, but it does not contain selectable text. Run OCR to create a text layer or convert the scan into editable text. -
Is Microsoft Word good for editing scanned PDFs?
Word can be useful for simple conversions, especially if you want to turn a PDF into a Word document. It is not the best choice for complex scanned PDFs because formatting can change and OCR results may be limited compared with dedicated PDF OCR tools. -
Is it safe to use online OCR for scanned PDFs?
It depends on the document. Online OCR is convenient for non-sensitive files, but confidential documents should be handled carefully. For contracts, IDs, medical records, financial files, or internal company documents, offline OCR software is usually safer. -
What scan resolution is best for OCR?
For most printed text, 300 dpi is a good starting point. Very small or faint text may need a higher resolution. Avoid blurry, skewed, shadowed, or low-contrast scans because they reduce OCR accuracy. -
Can OCR read handwriting in a scanned PDF?
Some tools can recognize certain handwriting, but results are far less predictable than typed text. Printed text is much easier for OCR. If the document contains important handwritten notes, expect to review and correct them manually. -
What is the best app to edit scanned PDF files?
For a balanced workflow, use a PDF editor with built-in OCR, editing, conversion, and page management. PDFelement is a strong option for users who want to OCR a scanned PDF, edit text and images, export to Word or Excel, annotate, sign, and compress the final document without switching between multiple tools. Adobe Acrobat is another capable choice, especially for teams already using Adobe products.

