
PDFelement-Powerful and Simple PDF Editor
Get started with the easiest way to manage PDFs with PDFelement!
Python is a popular programming language that many people think is limited to building websites and applications. Python does more than these and is slowly becoming a major focus for data scientists because they can use Python to analyze data, automate tasks, and read PDF files.
Many people dint know that they could read PDFs with Python and other programming languages. Fortunately, this article gives you a thorough guide on how to read PDFs in Python, JavaScript, and C#.

Part 1. Read PDFs in Python
Python allows users to read PDFs in several ways using different Python modules. Some of the ways to read PDFs in Python using Python libraries include:
1. Use the PyPDF2 Module To Read PDFs in Python
PyPDF2 is one of the best Python modules to read a PDF file. In this section, we dig into what PyPDF2 is and how to use it to read PDFs in Python.
· What Is the PyPDF2 Module?
PyPDF2 module is purely a Python library that allows users to perform several major tasks on a PDF file. These tasks include extracting, merging, splitting, encrypting, cropping, decrypting, and adding watermarks and custom data to PDF files/pages.
· How To Read PDFs in Python with PyPDF2
Reading PDFs in Python with PyPDF2 is not a rocket science task. The following code snippet illustrates how to read PDFs in Python with PyPDF2.

Step 1 With the PyPDF2 library installed, you need to invoke the PyPDF2 module and import the PDFFileReader class to allow you to view and read your PDF file.
Step 2 Open the target PDF document in the read binary mode, then create an object (temp) to read the target PDF document.
Step 3 Read and extract the desired pages of the target PDF object you created above and set the number of pages you want to extract.
Step 4 Pass the print function to print the selected PDF pages.
2. Use the PDFminer.six Module To Read a PDF in Python
PDFminer.six module is also another popular Python module that allows users to read a PDF in Python. Like most other modules, it is not complicated, and you can easily understand it.
· What Is PDFminer.six?
PDFminer.six is a community-maintained Python package that allows users to extract information from a PDF file. As the name suggests, PDFminer-six is a fork of the original PDFminer. It extracts PDF texts directly from the respective PDF source code. PDFminer.six is also designed modularly, and users can replace each component individually.
· How To Read PDFs in Python With PDFminer.six
PDFminer.six allows users to extract and read texts from a PDF document in Python with simple code. The following code snippet illustrates how to extract and read a PDF document with PDFminer.six in Python.

Step 1 We import the extract_text class from the PDFminer. High_level library.
Step 2 Use the extract_text () module to extract and read text from the target PDF.
3. Use the Textract Module To Read a PDF in Python
Textract module is a Python library that automatically detects the type of file extension and then uses respective technology to parse and extract that file's contents. You can therefore use it to read a PDF in Python.
This module is useful if you need a single unified command to extract and read PDFs in Python. The following code shows how to read a PDF in Python using the Textract module.

The program imports the Textract module and then uses the process method to detect the current file type and extract the texts.
4. Use the PDFplumber Module To Read a PDF in Python
PDFplumber is another popular and useful Python module. This library is more potent compared to other Python modules like PyPDF2. It uses the open () function to read the target PDF file. The following code shows how to read a PDF in Python with the PDFplumber module.

- We first import the PDFplumber module and then open the target PDF with the open () function.
- The next code specifies the page to be extracted and printed for reading in the subsequent line.
5. Read PDF Tables in Python
If your PDF contains tables, you will need a specific Python library that can extract and read tables. Fortunately, you can use the tabula-py or Camelot-py libraries to read PDF tables in Python.
For tabula-py, use the following sample code snippet.
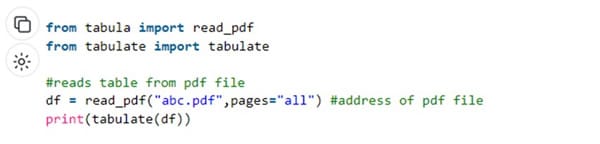
The read_pdf () reads the data from the table in the PDF file whose address is specified in the arguments.
The tabulate () arranges the table data in a table format.
For Camelot-py, use the following code snippet.
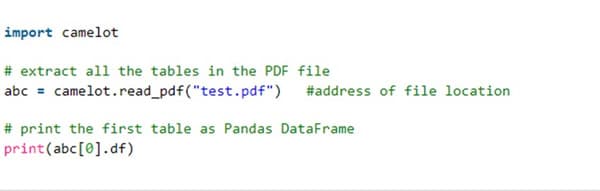
The read_pdf () function reads the data of the table contained in the PDF whose address is specified in the arguments.
The tables [index].df points to the target table of a specified index.
Part 2. Read PDFs in C#
C# is also one of the best programming languages that you can use to read PDFs. The C# syntax is not that complicated, especially if you have a background in computer programming languages.
What Is C#?
C#, pronounced as C-sharp, is a popular object-oriented programming language used to create robust, secure, and durable apps. Microsoft created this program, and it belongs to the family of C languages, including C, C++, Java, and JavaScript.
C# runs on .NET Framework and continuously evolves to give room to new workloads and emerging software design technologies and practices.
How To Read PDFs in C#
While C# allows users to create secure, robust, and durable apps, it also allows users to read PDFs. The following steps show how to read PDFs in C#.
Step 1 Download the iTextsharp assembly to your device from the itextsharp download page. Once downloaded, extract it to the project.
Step 2 Add iTextsharp namespaces to the program, as shown below.

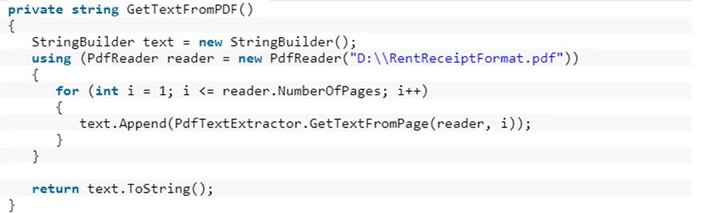
Step 3 Create a private class to get texts from PDF and return the texts in string data type as illustrated by the following code.
Part 3. Read PDFs in JavaScript
JavaScript is another popular programming language that you can use to read PDFs. In this section, we dig into how to read PDFs in JavaScript.
What Is JavaScript?
JavaScript is a scripting web language that allows users to create complex web page features like interactive maps, graphics, scrolling video jukeboxes, and various displays. It forms the third layer of the standard web technologies that also involve HTML and CSS. JavaScript is often used to implement the dynamic behavior of web pages.
How To Read PDFs in JavaScript
JavaScript also lets you read PDFs by extracting PDF content using PDF.js. However, the whole code is long and can be challenging if you are a newbie.
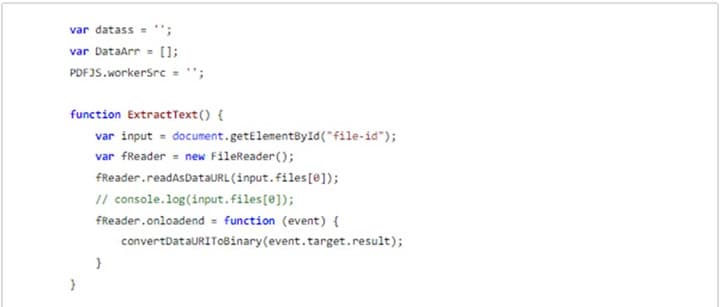
Step 1 To begin with, convert the contents of the target PDF to ArrayBuffer.
Step 2 The ArrayBuffer is then passed to PDF.js, and the text is read using the getDocument () method.
Step 3 Now, each page in the PDF file is extracted using the getPage () method.
Step 4 Extract each page of the PDF document using the textContent.items method.
Part 4. Read PDF Without Python or Other Programming Languages
Programming languages are useful in reading PDF files. However, understanding and memorizing the syntax is not a joke. Programming languages are difficult, and one must learn and familiarize themselves with the respective syntax before using them. Otherwise, you will struggle to connect the dots and read PDF files effectively.
Newbies are therefore recommended to use dedicated PDF software to read their PDF files. Unlike programming languages, PDF software provides labeled icons/buttons that remove the need for codes. PDF software is easy to use, and you don't need to learn any syntax.
Wondershare PDFelement – Simplify PDF Reading
Wondershare PDFelement is a powerful PDF software that makes it extremely easier to read and interact with PDF files. It simplifies your reading by giving you several features and options to read your PDF files depending on your needs. You can use various reading modes and customize your reading preferences to meet your reading needs.

Furthermore, its annotation features can highlight, mark, and make notes on certain PDF contents. This program is fast, easy to use, affordable, and compatible with nearly all devices and operating systems. You can also protect, edit, annotate, organize, convert, print, compress, merge, share, fill PDF forms, and perform PDF OCR.
How To Read PDFs With Wondershare PDFelement
Reading a PDF with Wondershare PDFelement is a plain sailing task, as illustrated in the following steps.


 G2 Rating: 4.5/5 |
G2 Rating: 4.5/5 | 100% Secure
100% Secure
Step 1 Download, install, and launch Wondershare PDFelement on your device.
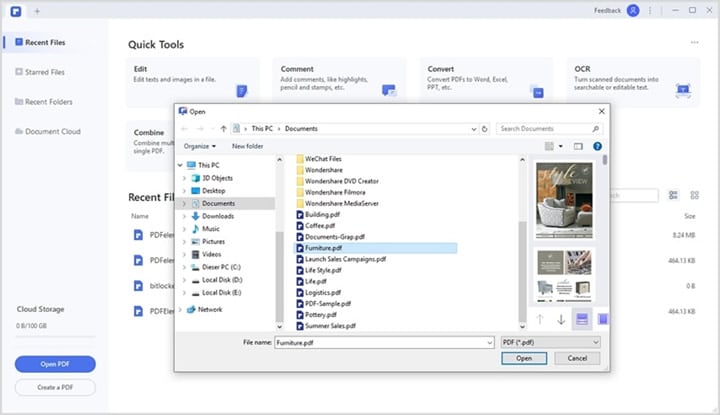
Step 2 Locate and click the "Open PDF" icon. Choose the target PDF file in the open file explorer window and click "Open" to upload it. Alternatively, you can drag and drop the PDF file on the interface.
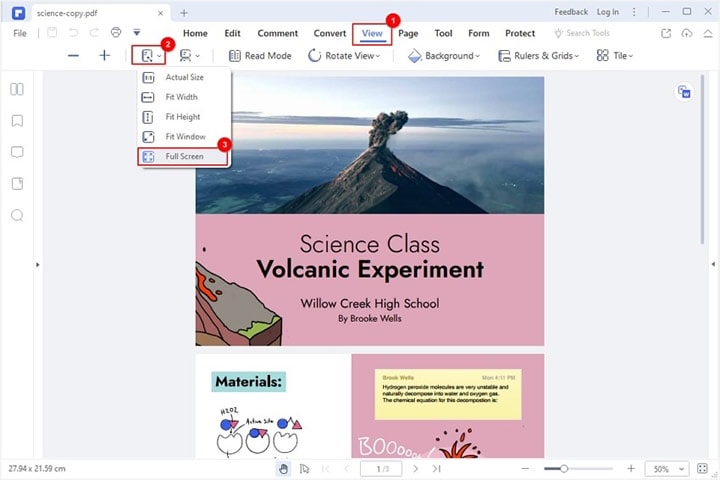
Step 3 Once opened, click "View" and choose desired reading modes from the secondary menu. You can choose the desired page layout, page orientation, document layout, themes, and viewing preferences.
Conclusion
After reading this article, you can now read PDFs in Python, JavaScript, or C#. However, it is a no-brainer that these programming languages require some expertise. If you are a newbie, you will struggle to comprehend and read PDFs using the respective codes.
Nevertheless, you don't have to crack your brain with codes simply because you want to read a PDF. Fortunately, good PDF software like Wondershare PDFelement simplifies how you read your PDFs. Choose the preferred method to read PDF documents easily!

